
LEARNING THE ARCHITECTURE OF DEEP NEURAL NETWORKS
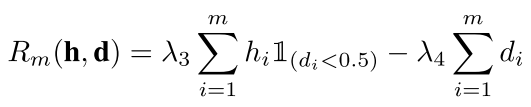
-
while for d = 1 it reduces to theidentity function.网络中每一层的各个w不一样 但是每一层的d都一样 要么是0要么是1 也就是要么这一层是线性的要么是非线性的 所以d是控制网络depth的 w是控制width的width是控制每一层的参数的个数 而depth是控制网络层数的因为我们的这几个参数w和d要么是0要么是1 所以我们的问题变成了ILP问题(binary)we require a method to learn binary parameters for w and d. To this end,其中直线代表线性 折线代表非线性就是我们每一层的网络的参数的个数 就是每一层节点的个数为ni目标函数为,we use the regularizer given by w(1 ? w) (or d(1 ? d))这种性质很好这样梯度就好求了 我们最后做一个约束所以把ILP变成了一个简单的问题光有一个这样的还不行 因为上面的那个公式只是让w和d趋于0和1 但是并没有对最后的模型的复杂度进行约束 所以我们需要加入一个约束来定义模型的复杂度the model complexity term is given by把这个和上面那个公式结合起来就是我们最后的结果了,把这种学习方法叫做 Architecture-Learning (AL)algorithm 就是不是以模值L1L2来约束了 而是以参数来约束这就是它们定义的激活函数 This reduces to the usual ReLU for w = 1 and d = 0. 也就是非线性的激活函数 For w = 1 and d = 0 it behaves similar to ReLU,whose parameters are given by the matrix product of the weight matrices of the original two layers.如上图所示,It is well known that two neural network layers without any non-linearity between them is equivalent to a single layer,LEARNING THE ARCHITECTURE OFDEEP NEURAL NETWORKS其中我感觉比较重要的一句话, ,
我的idea

-
2015-11-04 今天看了一篇比较不错的文章《Reasoning about Entailment with Neural Attention》 写的是 RTE 就是看看两个句子之间的entailment-Reasoning about Entailment with Neural Attention.pdf我的想法就是以后可以用这个东西来表达一个短文和一个statement之间的联系,我的idea以后这就是我的idea 以后有什么想法就写在这里,然后就可以看到我们的文章是否能蕴含出我们的答案其中的思想还是很好的 只要用neural 什么都好办 看看怎么扩展到大段的篇章上面, ,
文章好句子
-
以后就可以经常摘录比较好的句子在里面,从今天起 我要记录一些文章中出现的好句子,published dataset and rigorously evaluate results — most research concernsbuilding auxiliary systems that augment human database experts. 最近没有什么什么Open Question Answering Over Curated and Extracted Knowledge BasesIn a nutshell 简而言之,,
上一页 下一页