
也是在Squad上面做的,效果不好,但是很有意思,利用了很大的外部资源
-------------------------------
主要是利用了外部的资源来辅助Squad的阅读理解
先看看有一个叫做判别模型的东西 也就是 Discriminative Model
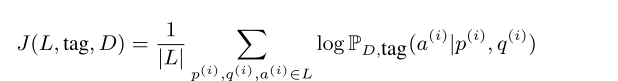
就是传统的那个产生答案的模型 其他很多人已经做过了
注意其中有一个tag就是为了后面服务的,因为这了的外部资源是这样的利用的 也就是一个encoder-decoder模型,在外部的wikipedia上面,用规则抽取一些答案,然后给定文章,答案,我们产生可能的问题,这个东西可以利用已有的Squad来训练,也可以用GAN来训练。但是这样产生的一个样本,就是属于模型产生的,也就是有一个label 也就是对这一个样本,是真正的(Squad)还是模型产生的(翻译出来的)。
然后我们看看这个生成式的模型是什么

但是这样训练出来的有一个问题, d_gen是指的generator的标签,也就是这个样本是生成的

也就是这样的产生的一个样本,可能会是这样的,给定一个a和p,产生一个a,这个a其实就是问题,那么那个生成式模型肯定直接就会直接给出答案了,只要把问题复制一遍,就可以了
所以作者在这里用了一些trick来搞定这个事情 也就是所谓的adversarial training
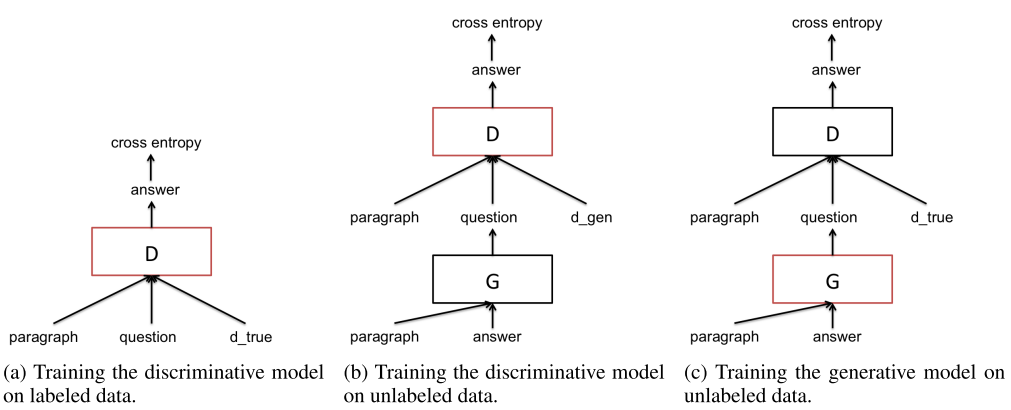
可以看到 先是在原来的数据上面用D训练一个判别式模型,然后在用这个G产生的样本来训练,最后再训练这个生成式模型。用的就是REINFORCE算法,因为对G来说目标函数是不可导的,注意那里的label 子啊第一个里面是d_true 在第二个里面是d_gen 也就是D知道这个样本是来自生成出来的,第三个里面又是d_true 也就是真正的样本对D 所以才能很好的训练G
最后的实验非常烂,而且也没有给出具体生成出的样本,所以我不知道这个东西是怎么中的
回复列表: