这个meta learning就是 learn to learn 主要是用一个网络学习另一个网络的东西
首先介绍一个文章 Matching Networks for One Shot Learning

应该是16年的nips
这个文章就是学习one-shot的这种东西 用的是类似 KNN的那种思路
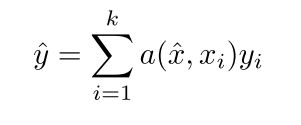
其中x^{hat}就是指的输入的测试数据,x_i是训练集的数据,这样可以看作是knn的一种表示
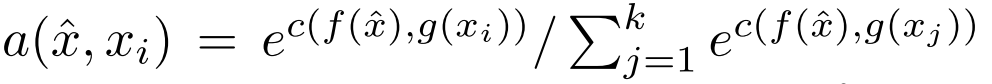
也就是我们用的这种attention的方法,来寻找这个最近的东西
注意 我们选的这个k个东西, 叫作 support set 也就是one-shot learning中那每一类只有一个数据的东西 支撑集应该是在knn里面有说 蓝本什么的
现在重点来了 其实我们看论文如果只看它的模型的话,大家都大同小异,所以这种模型不用看(怎么算f怎么算g) 主要是它对一个任务的介绍
首先是 在很多情况下 我们不是一个类别只有一个标签,那么我们怎么算这个one-shot呢?

也就是其实我们每次也就是取全集中一些类别的标签出来,

这一步就很清楚了 我们是先选label 比如我们有一个任务是城市分类,判断一个文本描述的是哪一个城市,我们候选城市有1000(|T|=1000)个,我们首先选label 也就是sample L from T 这个时候L很可能就是 ‘北京’,‘上海’。然后我们根据这个L去从训练集选取支撑集S 也就是随便找两个标签是北京和上海的样本。然后我们选取一个batch 这个就可以很大了,但是标签也是只能是这两个。然后按照上面公式2来训练,这样就是可以构造我们的one-shot的训练过程了。
然后我们再来看下一篇文章
Meta Networks
主要是meta-learning
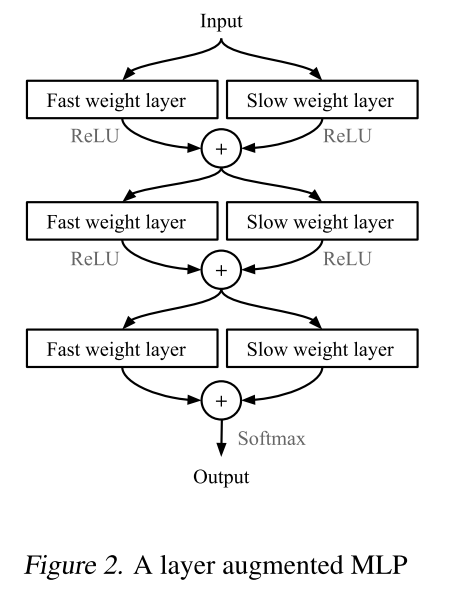
整体结构是下面这样的
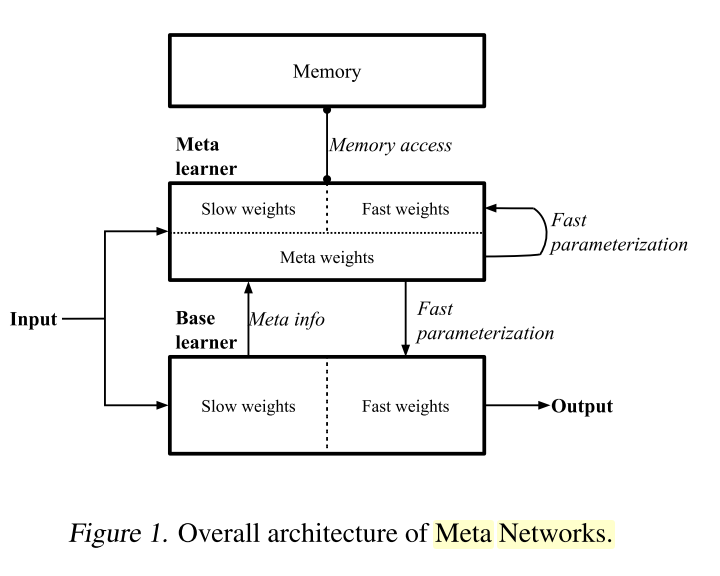
首先是一个base learner 学习输入输出 有自己的slow weight
然后 它提供一些东西给meta learner 这个东西就是他的梯度
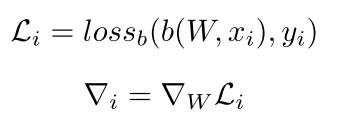

看到没 其实也就是那个支撑集 基本上都是一个类别一个数据的那种,这样才会固定有多少个导数
然后 我们的meta-learner拿到这些信息之后,开始产生一个新的weight W* 这个新的weight是base learner的fast weight 也就是每一个数据都有的一个独特的weight
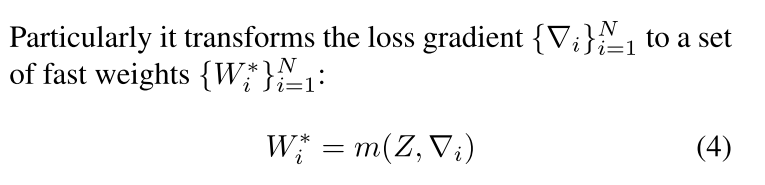
看到没 就是将梯度转化成那个fast weight
然后这个meta-learner也有两个参数 一个是fast 一个是slow weight
但是这个meta-learner的fast weight是自己学的 我们看看怎么产生这一切的
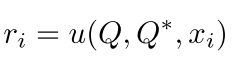
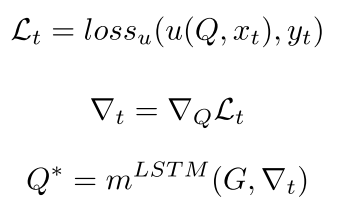
可以看到也是自己逗自己玩,但是这里面用了一些新的数据来学习这个Q* 也是另一些支撑集
有了这些 我们就可以算哪个W*了
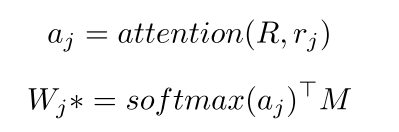
其中M是
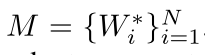
也就是刚才上面那个导数求出来放到的地方,每次都在变
两套参数同时作用的时候 是这样的
、
最后就是为了让下面这个目标函数最小,因为W_j^*是哪个meta-learner的参数,所以也可以学出来,所以现在都学出来了

说的很清楚 ,也是每一个任务 (其实就是上一篇文章的那个batch) support set是每一类只有一个标签的那个支撑集,然后每一个meta-learner其实是只在这个支撑集上面得到输入
也就是cross-task的信息。但是这个base-learner就是跟support set无关了,而是对当前的输入(3)来改变
具体过程我猜就是 来了一个样本,先用当前的W 算出对支撑集的梯度,然后得到了W* 。再来一个数据,再算。。。。
回复列表: