最近听这两个词的次数非常多,在这里总结一下:
--------------
首先one-shot learning 也就是看到的机会很少,会产生新的类别,这种现有的很难进行区分。
最好的文章《Attribute-Based Classification for Zero-Shot Visual Object Categorization》
但是有一个方法,就是叫做提取 attribute 如下图
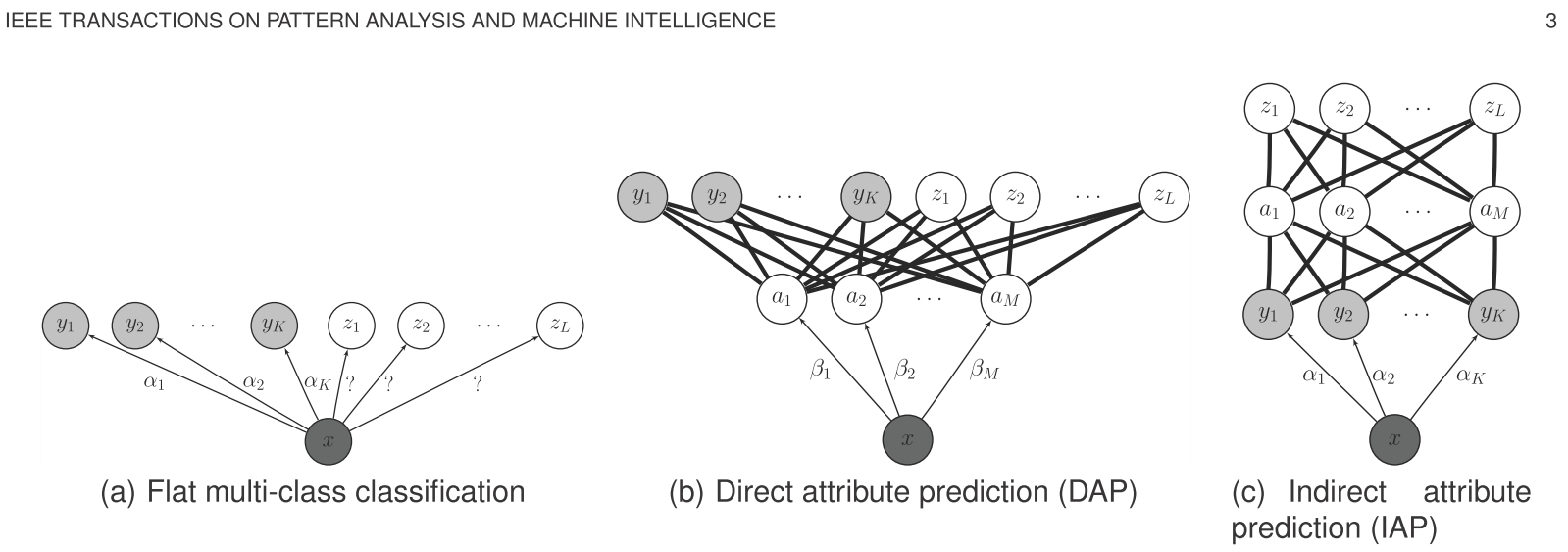
可以看到b和c都是先提取出这个attribute 然后再进行推理。
过程不细说了,总的来说就是:
1)对每一个class(包括test set里面的),人为的给分配一些attribute(这样做总比标新的数据要方便一些)
2)然后学这个输入到这些attribute的映射。
3)然后根据下面这个公式,得到这个类别属于什么。
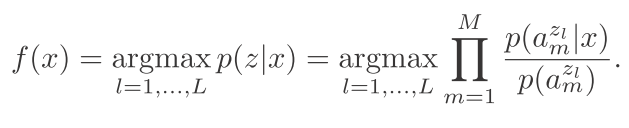
记住一点,我们的这些类别对应的属性,都是人为给的。
简单吧, 我们可以用别的方法,比如我现在做的,就是让GAN自动学出来那些01的属性,然后这个句子就是这了,然后来的新的句子,看它的隐含层(01表达)就可以生成新的属性
----------------------------------------------------
one-shot learning
就是有的样本只见过一两次,怎么办。
有一个叫做meta-learning的方法可以做,但是我还没研究透。
现在只是说一个比较简单的 方法啊,就是1nn 哈哈,在训练集里面找那个离他最近的那个样本的label 哈哈 简答吧
当然工作有很多,比如下面这个是比较经典的
《Matching Networks for One Shot Learning》
主要结构就是
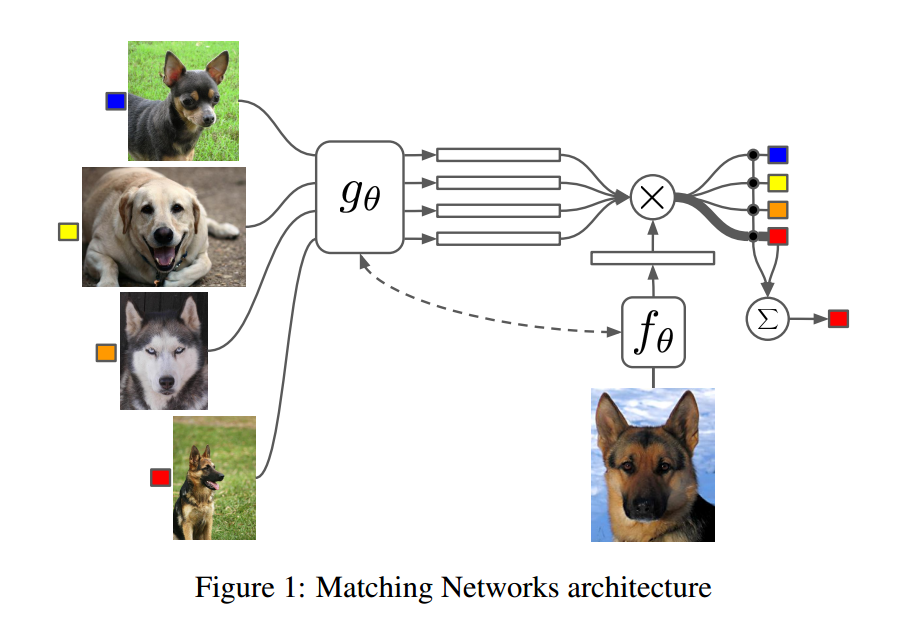
回复列表: