最近因为要搞一个东西,所以又重新玩了Java。
项目是这样的 ,读入一大堆文本(总大小超过200g,分成将近1000个文件,单个文件500m左右),然后对每个文件进行处理,统计词频,或者其他一些操作,还要把处理后的东西输出到另一堆文件里面。
-----------------------1,并行-------------------------------------
首先,读入一个文本之后的文件大约有5000行左右,所以可以每次读入一个文本之后,不要用for each遍历,而是用Java8的parallelStream遍历,这样会自动并行,然后这样的话处理文档的时间会加快很多,因为各个线程之间的相互依赖很小,所以可以很快速的进行并行计算。
-----------------------2,IO+计算----------------------------------
上述的方案,其实还是从总时间轴上看是串行的,因为要么磁盘干活,要么cpu干活,这样不是一个很好的选择。我们的一个文件大小在500m左右,在一般弱一点的机械硬盘上面读入很花时间。因此这样的大量时间都被cpu等待过去了,很不高效。因此,我们设计一套生产者,消费者模式。
具体来说,我们设计一个仓库(在我的程序里面就是List<String>),然后生产者就是当这个仓库没有东西了的时候,往里面放东西(从io),然后消费者就是看到仓库有东西,就开始处理。
具体来说,我们定一个List<string>之后,生产者开始,它会继承Thread类,也就是可以并行计算的 。
public void run()
{
load();
}
private void load()
{
file_lst.forEach(this::load_one_file);
synchronized (Done)
{
Done = true;
}
}
private void load_one_file(String filename)
{
System.out.println(filename);
String content= FileUtils.readfile(filename,"utf-8");
System.out.println();
String[] lines=content.split("\n");
synchronized (JsonLines)
{
while (JsonLines.size()>=max_produce_number)
{
System.out.println("生产者阻塞,列表大小:"+JsonLines.size());
try
{
JsonLines.wait();
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
Collections.addAll(JsonLines, lines);
JsonLines.notifyAll();
}
}
可以看出来,其实这个生产者就是从Jsonlines里面放东西,如果读入了一个文件之后,首先判断是不是生产太多了(因为不可能一直往仓库里面放,会内存溢出),如果满的,就等待。这个时候资源被消费者使用,消费者消费完毕之后,我们再将这个读入的lines加入到Jsonlines(仓库)里面。并且通知等待这个实例的线程(也就是消费者)我这里又有数据了,你可以用了,然后继续读入资源。
消费者和这个差不多:
public void iterate()
{
while (!Done||JsonLines.size()>0)
{
List<String> lst;
synchronized (JsonLines)
{
while (JsonLines.size()==0)
{
System.out.println("数据不够多,还得等生产者生产出来!");
try
{
JsonLines.wait();
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
lst=new ArrayList<>(JsonLines);
JsonLines.clear();
JsonLines.notifyAll();
}
deal_lines(lst);
}
}
可以看出来,就是也是一直等待,然后等到成产者有了之后,就先copy一份出来,把仓库清空,然后跳出来处理。(deal-lines)
注意,使用这种方法。我们可以使得两个东西并行进行,效率大大增强。
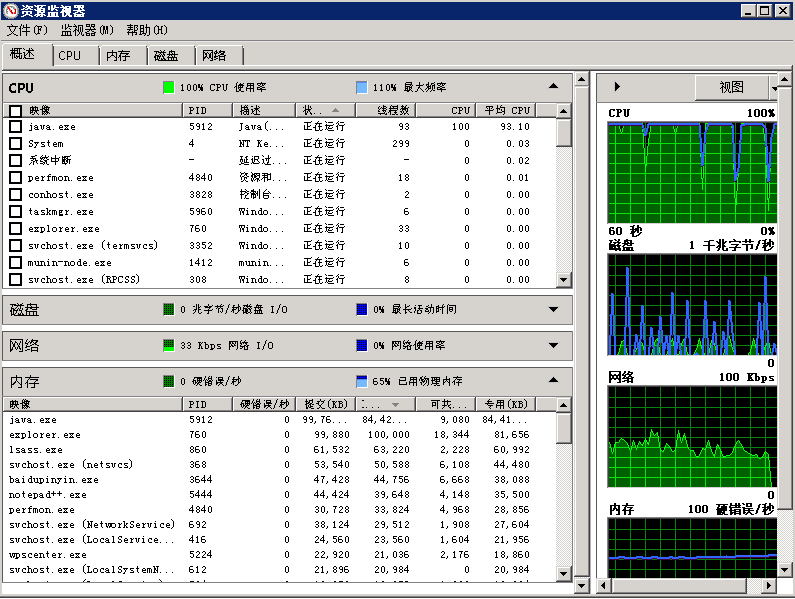
可以看出来cpu还有硬盘都在加班加点的干活。
不足,现在其实遇到的不足就是我们在生产者生产完毕之后,消费者在用的时候,首先得拷贝一份副本,原因:因为如果不拷贝副本,那么消费者的并行ParallelStream会很低效,因为每次算的时候都要检查这个变量的锁出来了没有,所以不行。但是这个拷贝副本的操作狠话时间。如下图:
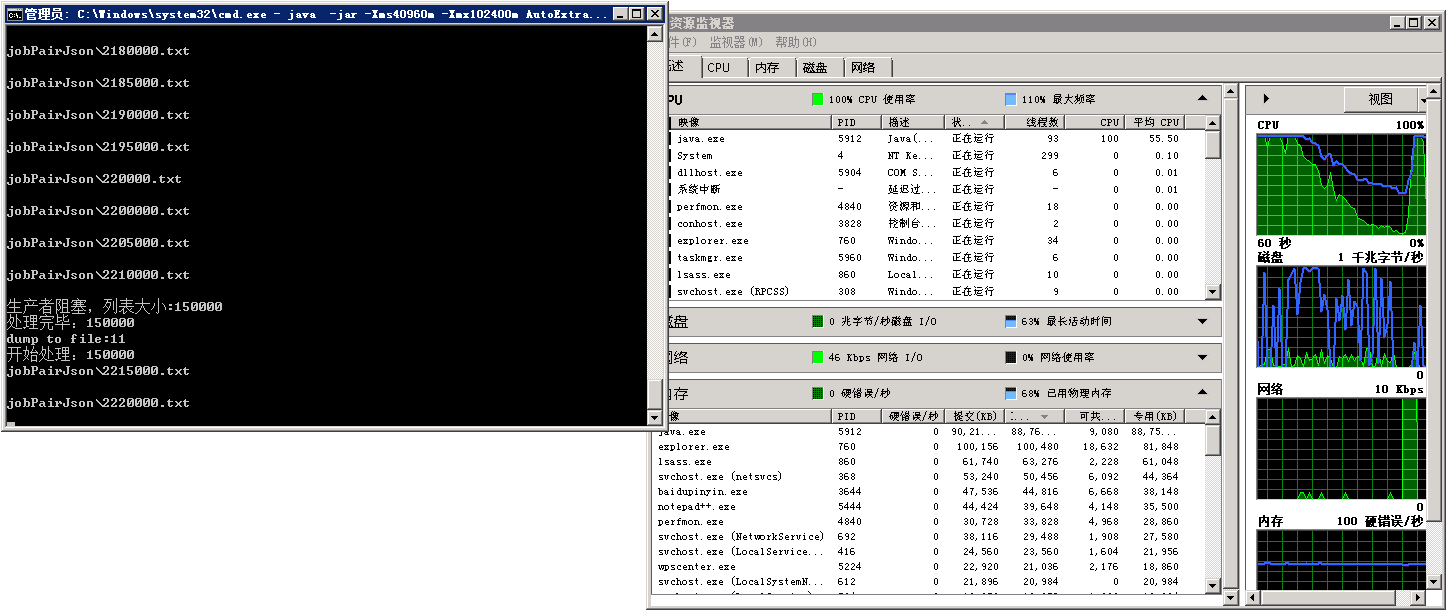
可以看到这个处理完毕之后,消费者下一轮进行之前,会首先拷贝,然后这个就是纯内存操作了,没法进行任何操作(Jsonlines被锁着)
但是整体效率还是有所提升的。
---------------------------3, future---------------------------------------------------
每次这种拷贝副本的方法太耗费时间了,怎么提升?
1)快速拷贝副本的方法,有没有?
2)不拷贝副本,因为生产者往Jsonline里面导数据的频率不是特别高,所以在它IO的时候,我们进行处理(直接不拷贝而是直接用),然后P在往外dump数据的时候,C等待。这个可能会快一点。
P.S. Java8 简直就是……………………
回复列表:
匿名发表于 Jan. 17, 2019, 4:53 p.m.
Java8以后的并行化特别好用,生产者消费者也很好。在Python中只能用queue