前一段时间因为要做learning to ask,所以把以前NMT的那点又给捡了起来,只不过这一次是用pytorch实现的。
----
首先看模型,就是一个简单的关注机制。
1)encoder
是一个先用LSTM底层表示,然后再用self-attention 进行关注的一个encoder
Encoder(nn.Module): (source_vocab_sizen_embeddingn_hiddenn_layer): (Encoder).() .embedding = nn.Embedding(source_vocab_size + =n_embedding) .rnn = nn.LSTM(=n_embedding=n_hidden==) .projection = nn.Linear(* n_hiddenn_embedding) .attention = SelfAttention(n_embeddingn_layer) .att = nn.Linear(n_embedding=) (inputs): word_embedding = .embedding(inputs) encoder_representations_ = .rnn(word_embedding) encoder_representations = F.leaky_relu(.projection(encoder_representations)=) encoder_representations = .attention(encoder_representations) value = .att(encoder_representations) score = F.softmax(value) output = score.transpose().bmm(encoder_representations) encoder_representationsoutput
self-attention也比较简单,就是几个block堆叠在一起
AttentionBlock(nn.Module): (n_input): (AttentionBlock).() .conv = nn.Conv2d(==* n_input=(n_input)=()) .q_U = nn.Linear(* n_inputn_input) .p_U = nn.Linear(* n_inputn_input) .v = nn.Linear(n_inputn_input) .project = nn.Linear(n_inputn_input) nn.init.xavier_normal_(.q_U.weight=) nn.init.xavier_normal_(.p_U.weight=) nn.init.xavier_normal_(.v.weight=) nn.init.xavier_normal_(.project.weight=) (representationshiddenlinear): F.leaky_relu(linear(torch.cat([hiddenrepresentations]-))=) (representations): c1c2 = F.relu(.conv(representations.unsqueeze()).squeeze().transpose()=).split( representations.size(-)-) s1 = .get_hidden(representationsc1.q_U) s2 = .get_hidden(representationsc2.p_U) score = F.softmax(.v(s1).bmm(s2.transpose())) representations + score.bmm(F.leaky_relu(.project(representations)=)) SelfAttention(nn.Module): (n_hiddenn_layern_head=): (SelfAttention).() .n_head = n_head .att = nn.ModuleList() _ (n_layer): en = AttentionBlock(n_hidden) ln = nn.LayerNorm(n_hidden) .att.append(nn.Sequential(enln)) (representations): one .att: representations = one(representations) representations
decoder就更简单了,就是一个自我表示的一个东西。先用个LSTM表示,然后在和source的表示进行attention,最后输出
.decoder = nn.LSTM(=n_embedding=n_hidden=) .att_U_q = nn.Linear(n_hiddenn_hidden // ) .att_U_a = nn.Linear(n_embeddingn_hidden // ) .att_v = nn.Linear(n_hidden // n_hidden // ) .project = nn.Linear(n_hidden + n_embeddingn_embedding) .output = nn.Linear(n_embeddingvocab_size + =)
注意,因为我们用了sentencepiece,也就是unigram-language model 。所以中英表示为一个词表,所以和文摘一样词表一致。
翻译的时候没有用beam search,不知道为什么用了beam search后效果反而不好,这里加个TODO吧。
其实,我还实现了很多模型,包括coverage,还有transformer,但是这些模型占内存太大,我的vps只有2g内存,忍痛给隔了。
最后的项目地址为:
https://bingning.wang/translation/
github:
https://github.com/benywon/en-ch-NMT
一些展示的demo
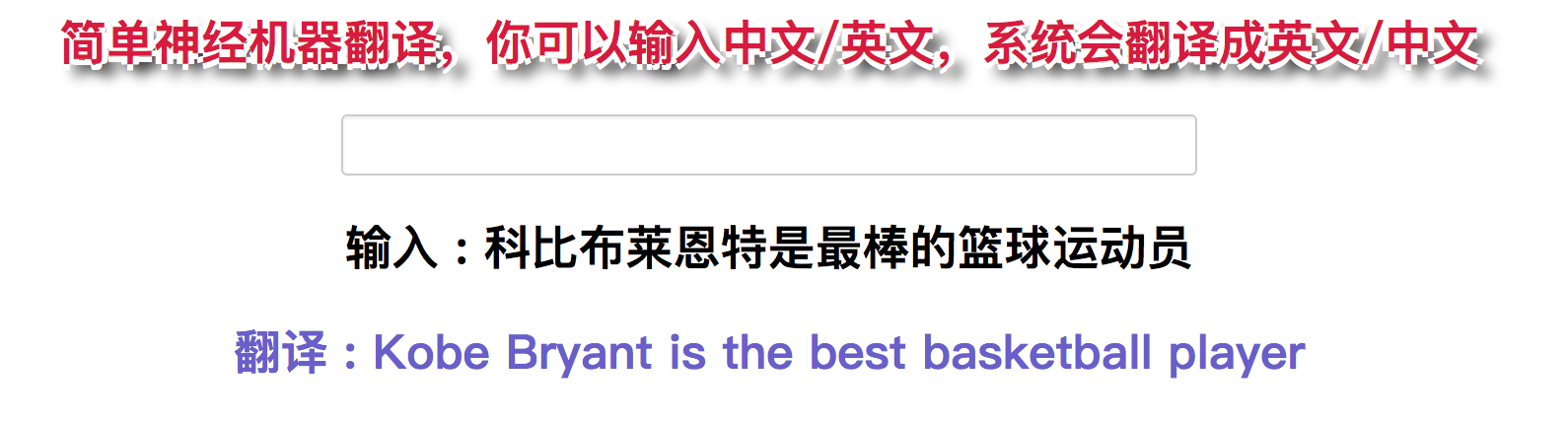
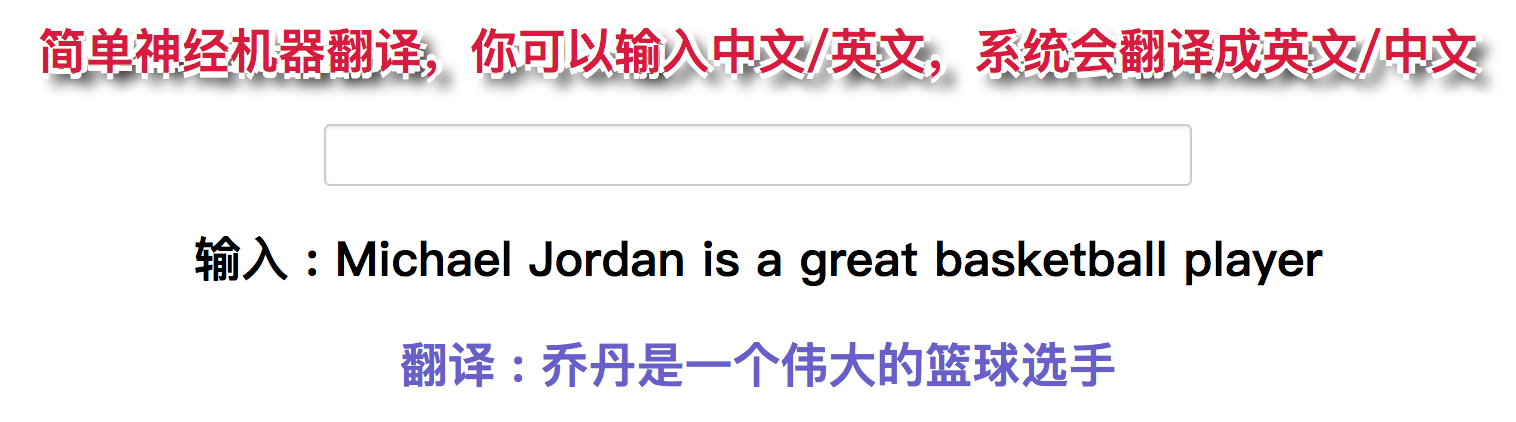
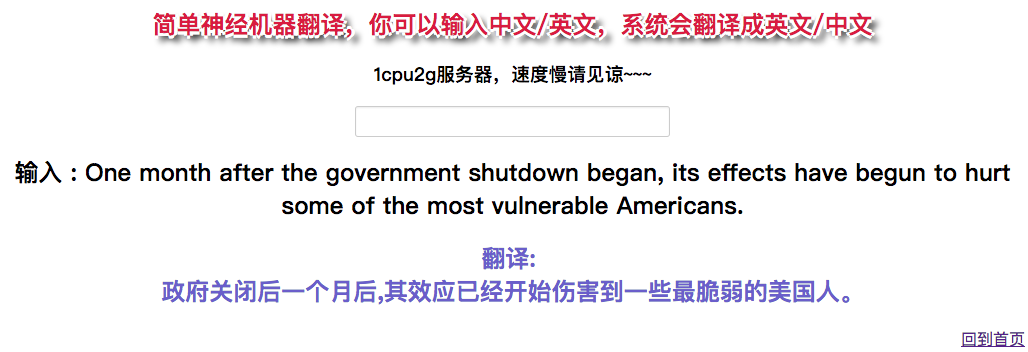
回复列表:
匿名发表于 July 17, 2021, 6:55 p.m.
对 于 阿 富 汗 , 我 意 识 到 — — 这 是 西 方 国 家 也 不 曾 意 识 到 的 — — 即 在 我 们 成 功 的 背 后 是 一 个 这 样 的 父 亲 — — 他 能 认 识 到 自 己 女 儿 的 价 值 , 也 明 白 女 儿 的 成 功 , 就 是 他 自 己 的 成 功