最近在搞一个NMT的东西,在GPU上面训练,然后放到mvps上面inference。
mvps只有1核2g,所以速度很慢。只能用cpu版本的pytorch,但是我发现一个很奇怪的现象,就是当模型被加载之后,速度异常的慢,非常奇怪。翻译一个五个词的句子竟然要十几秒,实在是不能忍。
-----以下全部在mvps(cpu)上面实现------
我首先通过速度调试,发现,当我不加载预训练的模型,即所有的模型都是随机初始化的时候,我们的模型的速度还很快(同样是解码10个词,编码5个词)。但是当我们加载预训练的模型后,速度特别慢!!
使用 autograd的profile来进行调试:
发现两个很大的区别:

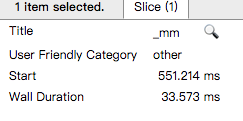
这个图表示未加载模型的时候的速度,基本上都很快,最上面可以看到1400ms左右就完事了。
其中的某一部分 操作的耗时为:
但是,当我们加载了模型之后,就发生了很大的变化:

可以看到总时间变成了10s左右,慢了很多,然后其中某一部分为:
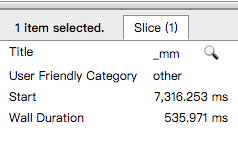
简直不能忍啊!!
=====================
经过精心调试,我发现了问题之所在:
原来,我在训练模型的时候,为了加速,使用了nvidia的apex进行混合精度的训练。
所以,当训练的时候,模型保存的时候,有一部分模型的参数,是FP16
但是cpu可不支持fp16,所以虽然也是用load_state_dict()来加载的,但是因为其中的很多数据都已经使很小的数量,所以可能会被动触发一些转化。
我甚至用了先把参数导成numpy再加载,也不行,确实是因为实际数据是fp16的。
最后,我换了一个思路,先用apex的amp进行混合精度训练,完事之后再用fp32最后finetune一段时间,最后再保存参数。
返现这样做之后速度参数就是fp32的了,速度有极大的提升!!!
happy NMT!!
回复列表: