------------------WHY-----------------------------
Currently, with the development of generative adversarial neural networks, many fancy models have been proposed to synthesize vivid picture. Take the example from ICLR2019 paper "Large Scale GAN Training for High Fidelity Natural Image Synthesis" (a.k.a. BIGGAN)for instance:

It is really hard for eyes to determine which pic is real and which one is fake, right?
As the output of the GAN is continuous variable so it is natural to apply GAN to image synthesize. However, when comes to the text generation, as each token is a discrete symbol, its not an easy work to apply GAN. As the gradient has been blocked in the output layer of the generator.
However, we can use many tricks to make the gradient flow to the generator, such as Gumble softmax, Policy Gradient or Straight Through.
But why should we use the GAN to generate sequence? Is the critic (or discriminator) in this setting is better than probability likelihood, or some fixed metric like BLEU or ROUGH?
So, In this demo I just generate the text from a naive language model. During training the seq-to-seq model is trained my MLE. During inference period we use generate sequence by random sampling.
This is an easy task, just right an nn.LSTM and output layer and embedding layer so we could generate the Chinese poetry!!! Sounds great, but this project is not very attractive, because someone who want a system (or AI, robots, whatever you like to call it) to generate poetry? Given that sometimes the generation is just grammar smooth but loses a lot of, yes, MEANING (神 in Chinese).
So, if you want to build an automatic poetry generation system, it should be conditional: the system should generate poetry based on some keywords. In this setting, the user could find some interesting clues behind the poetry.
---------------------HOW---------------------------
1) oh, it is a very simple task! just use the unconditional language model to enumerate as much poetry as it could and select the one that contains this keyword? Sounds applicable, but wait, if you input a word such as '云' ‘月’ '花', I bet the system would quickly find the target that satisfied this condition. However, when comes to the sophisticated words like '涞', '强子', this long-tail word may cause the system to take a long time to generate. So, sampling method is applicable but inefficient.
2) Seq-to-Seq: Like machine translation , could we just put the keyword as the source sequence and generate the target sequence thereof? The answer is yes, except for we should use another LSTM as the encoder to encode the keywords information and take the encoder representation as the decoder hidden state initiation. This is the current framework of my implementation. Nevertheless, the target of the model is still the MLE, which spare no priority over the keywords. In fact, we found this system could generate more keyword than unconditional one, it still takes a lot of time to generate long-tail words.
3) Target words de-uniform: Sorry I couldn't find a word to describe this method, so let just call it de-uniform. This corresponding to when use cross-entropy (or MLE) to optimize the model, instead of equal weight for each item we should set some items weight much larger than others. In the conditional circumstances, the model may learn to focus on the alignment of keyword to the generation, which is a promising way to implement.
4) Reinforcement Learning: Yes, if the model generates a sequence that contains the keywords, just reward it, otherwise give it a large punishment. This is similar with the third method, but may take longer time for the model to converge. I leave this to the future works.
Finally, Let's see some example of this demo:


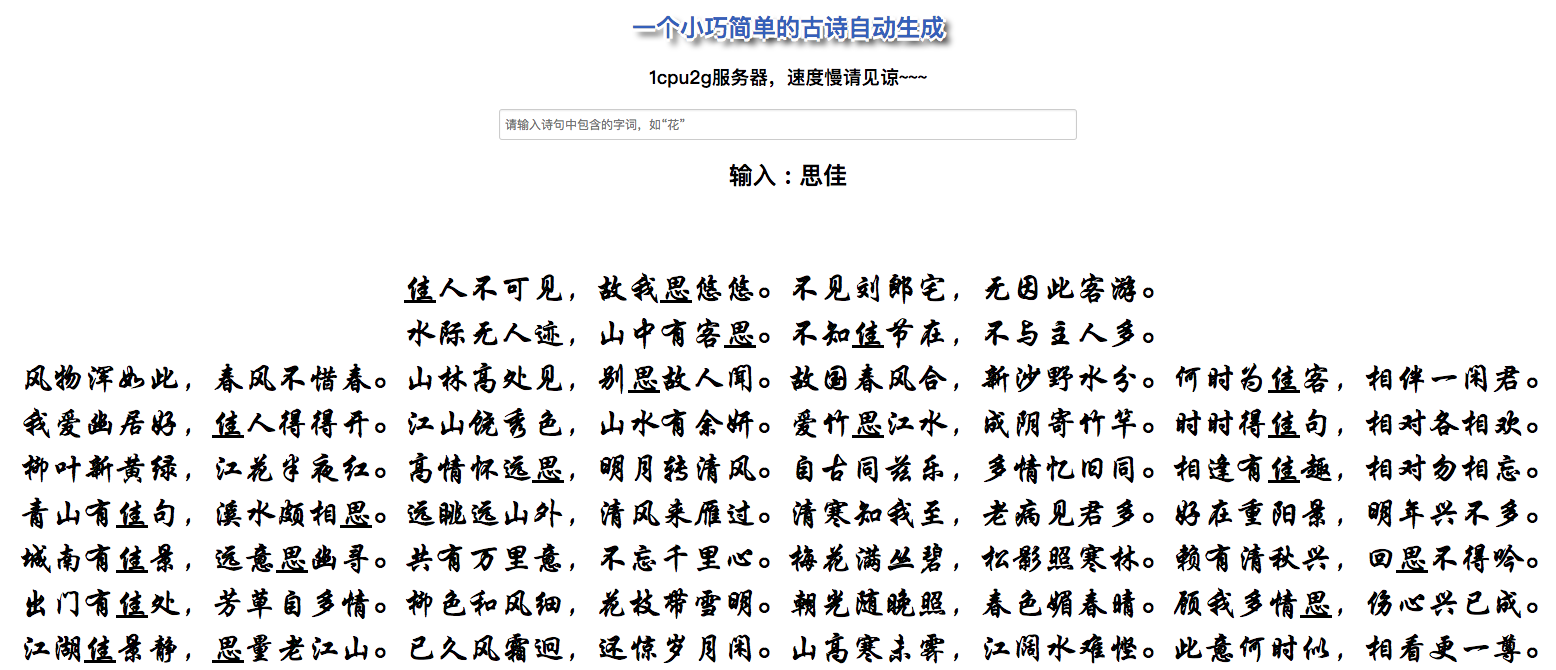
not so bad! Right? 
回复列表:
匿名发表于 Dec. 15, 2020, 11:37 p.m.
这个还挺好玩的