首先咱什么也不说,直接上图:
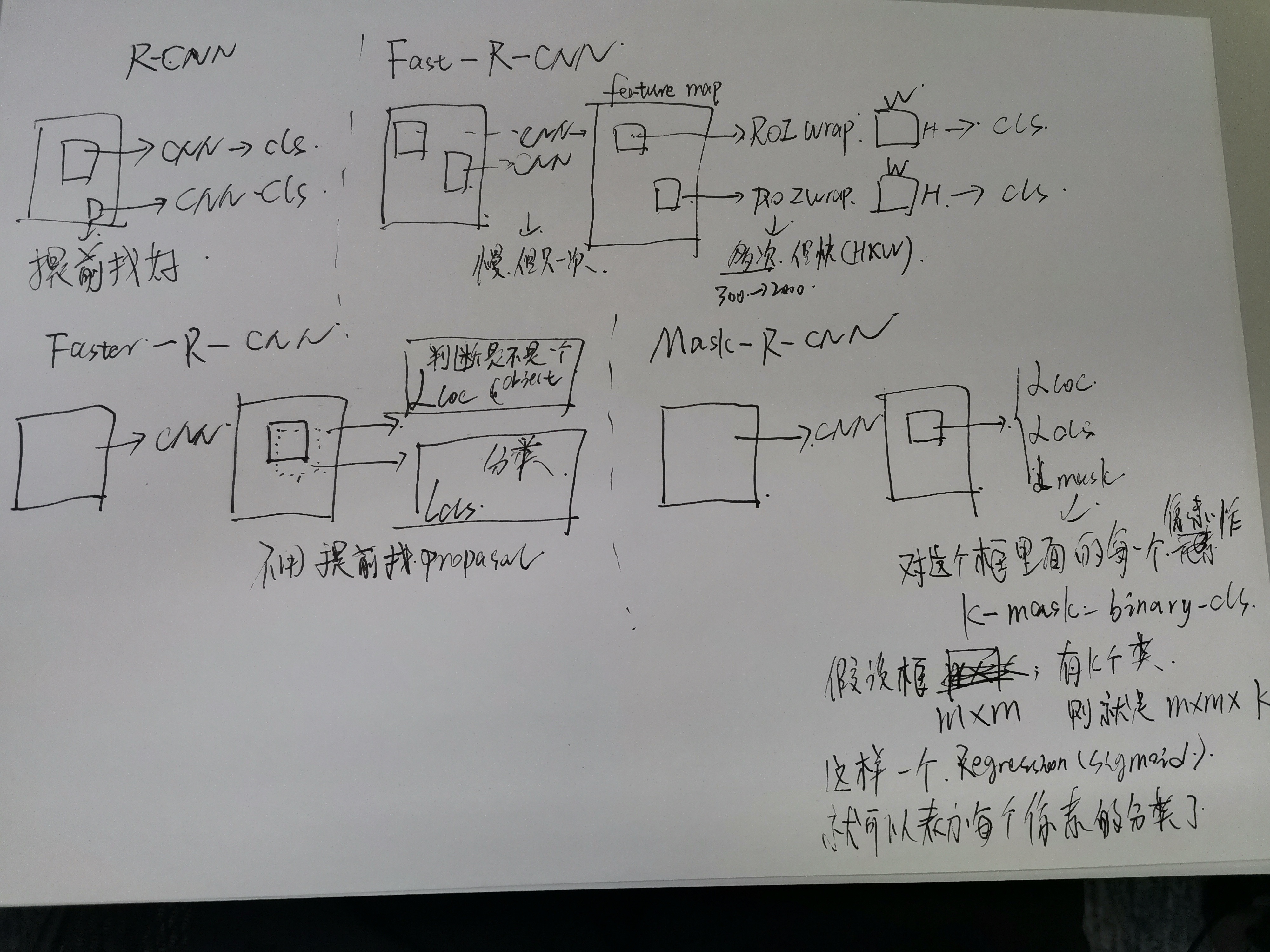
这个就是各个模块之间的主要分别,我手写出来用以分别。
在之前我们要有一个概念,就是最开始cv那些人在做这些事情的时候,是先通过一些启发式的方法,找到那个候选的方框。也叫做 candidate object regions 或者 candidate region proposals或者
因为这些会很多,所以对每一个region做cnn,然后分类就很慢,fast就是用feature先统一提取,最后在每个region上面做warp后然后直接用提取好的feature分类,
faster直接把那个proposal都省了,而是用一个模型先预测边界。mask-r-cnn就更棒了,但是模型没什么新意,主要是提出了一个叫做 instance detection的东西,这个东西把所有的事情都干了,加了一个mask,如下图:

其实也就是 不仅确定了边框,类别,而且把边框里面的哪一个像素是的,也给弄出来了,就是上图框里面纯色的部分,也叫做 mask。
整个模型也比较简单,如下图:
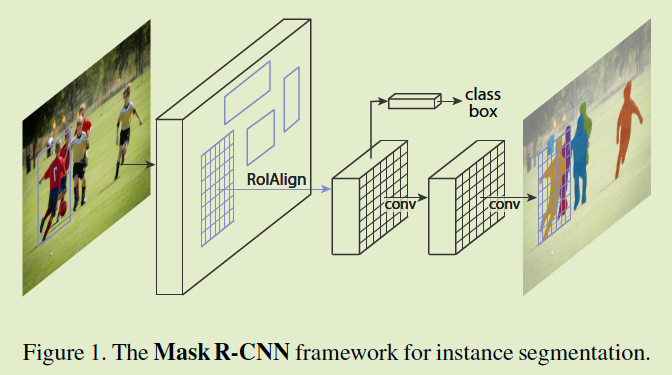
其中第一个conv之前还是和以前一样,只不过加了一个第二个conv,就是用来确定mask的。
这里面还有一些其他的 trick,因为以前的把一个框弄成正方形适合cnn来做,但是现在要mask,所以他们就设计了一种新的ROI确定的方法。

也就是以前的那种方法只能用来分类,但是现在要mask了,所以需要提出新的,具体我也没看懂 😄
以上就是这个MASK-R-CNN的主要的点,何凯明2016提出来的。不知道最近有没有新的model出来,我记得好像有用 RNN来做的,下次再说吧。
回复列表:
god发表于 Feb. 14, 2019, 11:50 a.m.
https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
这个文章讲了更具体是怎么做的,可以参考一下