In this series of articles, I will give a brief introduction to unsupervised machine translation. Which is the hot topic in MT community recently.
Part One:
1)Word Alignment:
This is the first part of most UMT systems. That is, given two monolingual corpora, how could we induce the corresponding word in two languages? Take the Chinese-English for example. We have two un-aligned vocabularies, and we want to aline each word in Chinese to English. This process could also be referred to word-level translation.
I will give a very popular method that adopted in many UMT system, which is called vector-mapping:
In a word, vector-mapping aims to map two words by word embedding similarity produced by skip-gram.
Step1: Learn a skip-gram word embedding for both source and target language.
This is a trivial task in current NLP and we can obtain good word embedding from many websites. But as for MT, sometimes equivalent words in different language contains a different number of word. For example, we use '热狗' in Chinese refers to the word 'the hot dog' (which is Sicong Wang's favorite  ).
).
In addition to the original word embedding, sometimes we also learn the bi-gram and tri-gram embedding, which also serves as part of the vocabulary we want to align. This is also called phrase-skip-gram. Sometimes we restrict the bigram and trigram size to avoid too much candidates.
The phrase-skip-gram is learned the same way as word-skip-gram, that is, the context word and negative sampling word is also unigram word. This would enforce unigram invariance.
Step2: Normalize the word embedding matrix:
This step is very easy as we normalize the word embedding so that the Euclidian distance is equivalent to cosine distance.
Step3: Inducing the seeds alignment:
This step is a primal step for the alignment. Given two word embeddings, namely X and Z, for each embedding, we calculate the similarity matrix of each language. Mx and Mz, Where Mx=XXt. Next, we sort each row of the similarity matrix (each row is sorted independently). Finally, we use each row as a vector and find the KNN in another matrix. For example, a word in chinese '好' in Mx is (1,0.8,0.7,0.5) where we suppose there are 4 words in Chinese, and the corresponding word in English 'good' is (1,0.7,0.4,0.6), so we can use this for alignment, as this two vectors are most similar.
Step4: Iterative Training:
This is the core step of the training:

where X and Z are word embeddings. This is similar to EM algorithm, where we first fix the D (alignment), which was initialized by Step3, and then find the projection Wx and Wz, then we use the new projection to derive the new D, and so on.
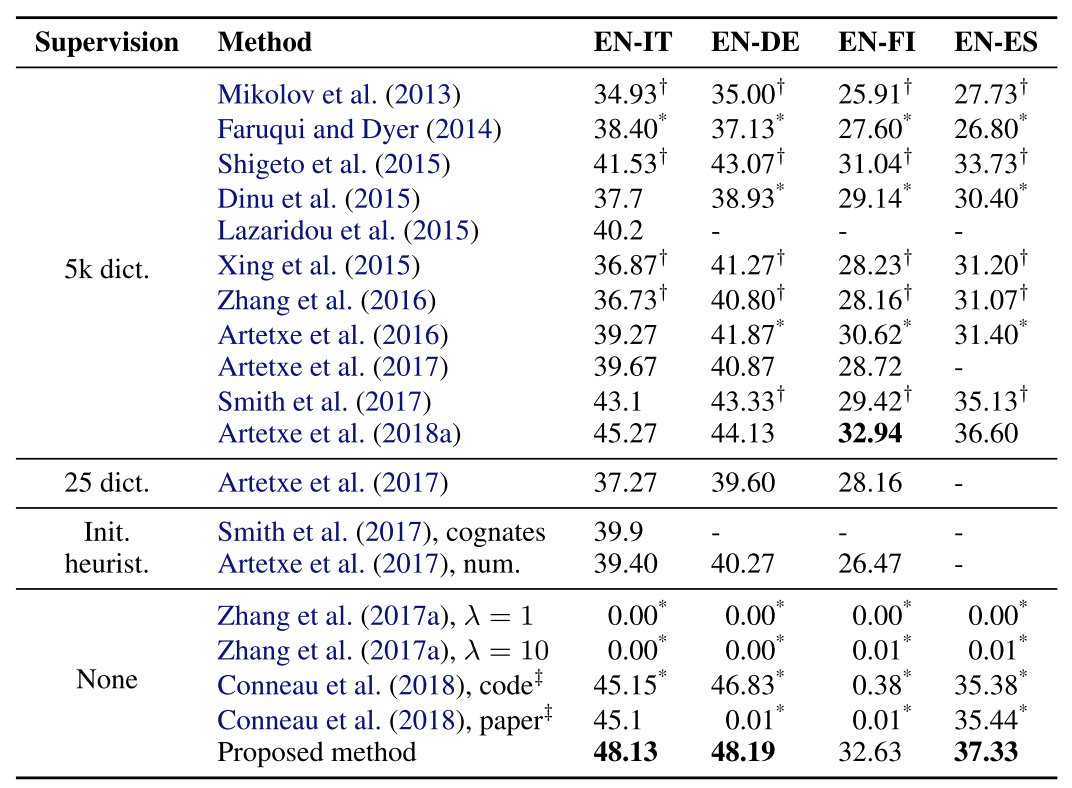
The above is the total process of word alignment in most MT system, I refer you to the paper 'A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings' for more details, including Frequency-based vocabulary cutoff and Symmetric re-weighting.
The result is also fancy and stunning, sometimes it also excels the supervised counterpart:
回复列表: