solr 在7.0版本之后发生了很大的改变,我以前写的analyzer好像都用不了了,今天给改了一下,如下:
1)更新ansj,用maven什么的都行
2)ansj_plug_lucene 这个很重要 以前都没用过,这个就是帮你实现了一个工厂模式的接口
3)nlp_lang,新版本的加入了这个nlp工具
1,2,3可以如下写:
<dependency><groupId>org.ansj</groupId><artifactId>ansj_seg</artifactId><version>5.1.6</version></dependency><dependency><groupId>org.nlpcn</groupId><artifactId>nlp-lang</artifactId><version>1.7.7</version></dependency>
<dependency><groupId>org.ansj</groupId><artifactId>ansj_lucene7_plug</artifactId><version>5.1.5.1</version></dependency>
然后就是配置schema
把其中的ansj分词改为
<tokenizer class="org.ansj.lucene.util.AnsjTokenizerFactory" type="index_ansj"/>
其中的type可以是下面这几个
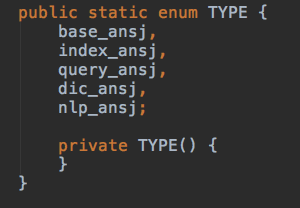
然后重启solr就大功告成了
回复列表: