非常好的一个文章,讲的是知识蒸馏和特殊信息的联合 我们一点点的道来:
Vapnik & Izmailov (2015) 说道:
我们的训练目的主要是:
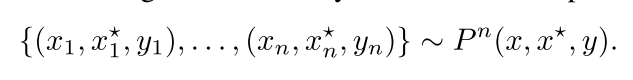
就是有n哥样本 我们有x和y 还有一个特殊的经过处理的或者有特殊意义的信息我们称之为x星,然后我们的拟合过程可以依靠这个x星,我们的有监督和无监督
都只是说有没有监督的信号,就是你做卷子有没有答案,但是这里的x星就起到了老师的作用
-------------------------
首先我们看Vladimir Vapnik大神的一些经典理论
-- VC theory,which characterizes the speed at which machines learn using two ingredients: the capacity or flexibility of the machine, and the amount of data that we use to train it. Consider a binary classifier f belonging to a
![]()
function class F with finite VC-Dimension |F| VC . Then, with probability 1 − δ, the expected error R(f) is upper bounded by
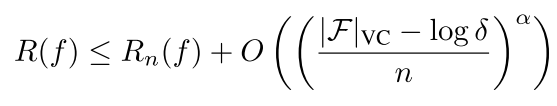

对一般的不可分问题 就是非常困难的 一般都是a=0.5 所以最后我们右边的那个上届的公式为
![]()
On the other hand, for easy (separable) problems, i.e., those on which the machine f makes no
training errors, the exponent is α = 1, which translates into machines learning at a fast rate of
![]()

所以我们可以看到有两方面
1)越是训练集越大 也就是右边的分母越大 则我们的训练损失和实际损失就越小
2)越是复杂的模型,它的VC纬越高,那么它训练出来的模型就和真实模型差别越大,因为上边的O是我们定义的上届 可以看出 linear model的
训练误差和实际误差应该很接近
------------------------
好了 然后我们现在有的很多新的工作都是让machines-teaching-machines: the paradigm where machines learn from other machines, in addition to training data.
比如词向量 先在语言模型上面获取知识 然后在我们的关系推到上面重新获取知识
2 DISTILLATION
这个第一步也是先和普通的一样
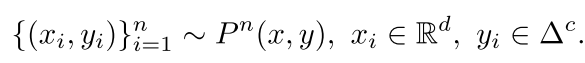
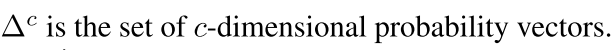
然后
这里其实最后的西格玛是一个sigmoid函数 就是映射到输出上面的 主要还是f
输出不解释
其中
这个就是知识蒸馏的表示方法 可以看的有一些区别
首先目标函数是带s下标的 表示不同的函数集合 和上面的公式中t不一样 是不同的函数集合
其次 这里加了一个老师信号 有个两步走的意思 首先 我们学习到比较好的teacher信息 就是上面的Ft 然后把它除以T之后表示一个
soft predictions from f t about the training data 就相当于老师了 然后有这么一个知识蒸馏的过程(就是把目标函数降低一个档次用更简单的模型去你和)
After distillation, we can use the simpler f s ∈ F s for faster prediction at test time.
因为在训练的时候这个fs是有右边的导师信号参与的
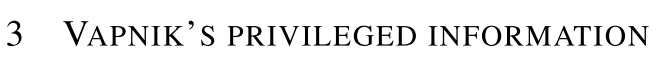
主要观点就是我们应该人为的加入一些 intelligent teacher, 就是上面最开始的X* 但是这些x星非常难获取 所以我们要另辟蹊径
------
有两个方面的观点: similarity control and knowledge transfer.
第1一个similarity control--
VV在09年发的文章中说道一个SVM+算法 如下
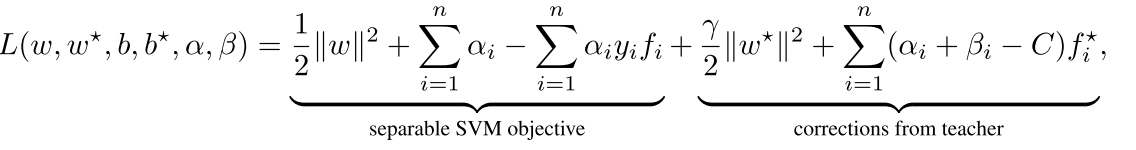
其中
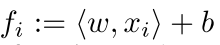
是我们在目标点的估计函数 就是decision boundary
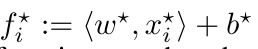
是那个地方相应的老师信号 我们可以将左边的看作可以分隔开的目标函数 右边是加的教师信号
我们可以把右边的f星看成一个在SVM里面的松弛变量,就是错误的点的惩罚项目,这样右边和左边组合到一起就是我们标准的SVM了,可以看看
ESL420页相关的公式就明白了
所以这里有了一个这样的trick 我们把那个错误分的松弛变量当做老师,也就是我们的老师可以告诉我们那个错误分的松弛变量的大小,学生
可能只知道正确和完全错误的 但是老师就可以给你指出来有些非边界点(错误点的)信息 所以这样你就可以好好学了
最后的总结就是
因为我们分界点的支持函数可能很复杂 但是对于那些松驰点我们的教师信号可能很简单
knowledge transfer--比较新的

就是先把我们的教师知识x星映射到一个蓝本u上面 然后用这两个东西去拟合我们的目标函数 注意这里没有原始输入x的参与
得到的一个教师公式ft 然后我们在让学生学这个老师 就是让他的的目标函数就是上面我们学出来的蓝本
注意这里是学生对每一个蓝本都学一个方程g 最后我们的目标函数就是在这个老师知指导下(已经有g了)学一个学生到目标y的映射
参数为a
可以看出来这也是一个三步走的策略
总结 学生就是他拿着x 但是不直接接触答案y 老师就是有一个x* 也就是它的背景知识 这个老师得先学习 就是从x*到y 她有经验了
所以这部分会很快(Ft简单) 然后她在把自己的这套经验交给学生 然后学生越到了老师的经验x->x* 然后就可以用这套经验进行答题了
(当然也得做卷子(x->y)才能提升)
=====================================================
最后 这篇文章的核心在这

就是先用教师的只是学习她到我们目标函数的映射
然后将这个知识soft一下 用T来soft 因为这个知识不一定直接能被学生用上
最后依靠上面Hinton那个知识蒸馏的公式 将学生学老师 学生学卷子一起学习 用拉姆达来调节这个学习过程
可以看出来是一个泛化的知识蒸馏过程 我感觉和VV的更像
可以看出来 在hinton的里面 教师信号是从x-y pair里面学的 因为这个过程很复杂 因为x-y的过程肯定是很不可分的
所以最后ft的复杂度要大于fs的复杂度 因为最后的fs同时可以学习老师 这部分知识被蒸馏了 所以复杂度降低
为了定性分析 我们要把这个东西当作一个完全的过程 就是HInton的知识蒸馏过程中的拉姆达是1 就是完全学习老师
================证明开始,请捂好耳朵=====================
首先 学生自己学习卷子的时候 它的学习错误率(VC角度)为
其中O表示估计的误差
然后西格玛是一个学生方程对真正整体方程的逼近误差
这个过程肯定很慢 因为错误率会很高(直接x-y的) 所以在VC纬度里面a=0.5
其次:老师的信号会很强大 就是老师学的会很快
就是老师的信号和目标函数很近了 所以这部分的VC纬度会很小 我们也把a设置成1 因为数据是可分的(X*->y)
注意这里的Ft不一定小 因为完全可分的两个平面(VC里的a大)你也可以很zuo的用一个很复杂的函数拟合~~~ 但好似这里是上届啦===
最后 学生到老师的学习速率也是个事儿 我们可以表示为
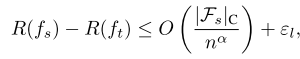
这里因为不知道老师的知识和学生的知识差多少 所以用了一个a来表示 因为这里不是确定可分和不确定不可分的
所以最后我们的学生在老师的鼓励下学习目标值的风险或者错误概率就可以这样表示
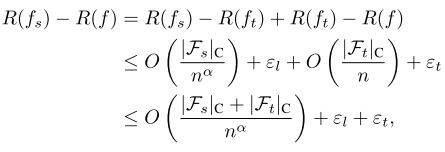
是他学习老师和老师学习目标函数的和 右边的不等式成立因为a《=1
所以 现在在教师参与进来之后 我们为了证明我们的过程(学生学习老师 然后老师再学习目标函数)有助于减小误差 就是等价于证明
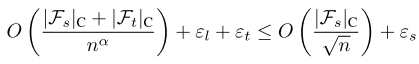
注意这个公式不一定成立 如果这个公式成立 则可以表明:
i) the capacity of the teacher being small, ii) the approximation error of the teacher being smaller than the approximation error of the student, and iii) the coefficient α being greater than0.5 就是左边的a很大 这样是增函数所以左边的O小 当数据量很小的时候 这个差别会很大 因为n很小 所以O在整个公式中会起作用了
为什么我们引入的教师信号会有用?
有一个观点是:The assumption of independence of cause and mechanisms states that “the probability distribution of a cause is often independent from the process mapping this cause into its effects”
Under this assumption, for instance, causal learning problems —i.e., those where the features cause the labels— do not benefit from semi-supervised learning, since by the independence assumption, the marginal distribution of the features contains no information about the function mapping features to labels. Conversely, anticausal learning problems —those where the labels cause the features— may benefit from semi-supervised learning.
就是这个从x-y的过程应该和其他的东西独立 那么我们的方法就没用了因为不管你怎么教 都不会影响x-y的过程
=======================
实验分为好几个步骤 分别是x*的产生过程不一样 比如只和答案有关 只和x有关 还有部分和答案有关 还有每个样例每个部分和答案相关
比如第一个:

就是只和答案相关 那个x只是和老师信号是距离的关系 没有什么
特殊的关系
这几个实验都是在说 只要你找对了老师 那么最后的结果一定会好 就是x*可以和label有点关系 那么我们的结果就有戏
总结:这次是第一次对VC维有个定性的概念 真是牛逼 知识蒸馏 先决知识 真是厉害啊!!!
代码:
论文:
![]() UNIFYING DISTILLATION AND PRIVILEGED INFORMATION.pdf
UNIFYING DISTILLATION AND PRIVILEGED INFORMATION.pdf
回复列表:
匿名发表于 Dec. 24, 2021, 9:48 p.m.
很棒!刚开始读的原文,有的地方不是很理解,看到你写的,理解了!