今天读了一个这个文章 就写一下读后感吧 以后准备就在这里写文章了
2016年2月19号下午 喝着朱哥的六安瓜片
======================================================================
传统的RNN有个毛病 就是每次都是循环的将以前的content应用到现在这个上面来 意思也就是每次都是只关注上一次的 就算是LSTM也是只是将上一层的给应用到这一层上面
我们可以看一下传统LSTM的样子
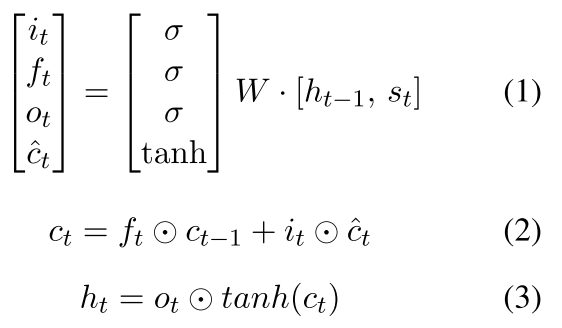
然后我们可以看到 每次这个公式3都是更新按以前的 所以作者说:which indicates poor generalization ability to long sequences as well as a significant memory wastage for shorter ones
现在我们换一个
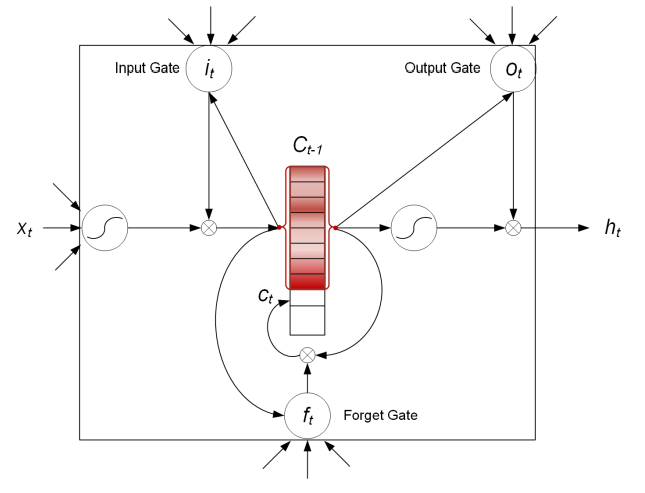
可以看到现在的核心区域中我们的那个Ct是一个将以前所有的东西都存下来的memory了 这个跟以前的memory Network如出一辙
现在更新的时候就变成
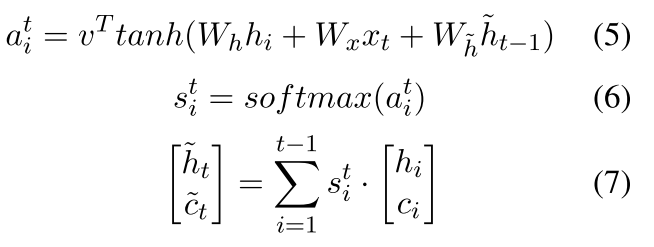
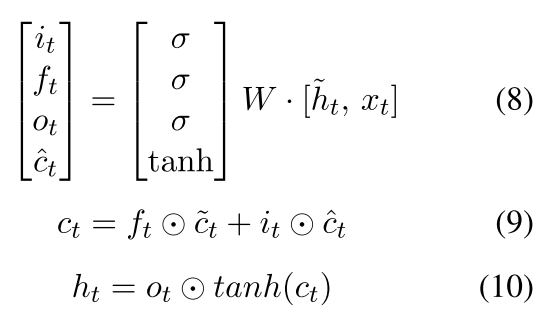
也就是 我们现在的(7)是我们的真正的以前的隐含变量了 就是我们将以前的东西换成一个可以将整个句子包含的东西
所以我们现在的model就是I一个attention based的了
作者还弄了一个双边的就是编码解码的东西 但是只不过是为了类似翻译或者其他的问题里面 我们可以看到这个东西像这样
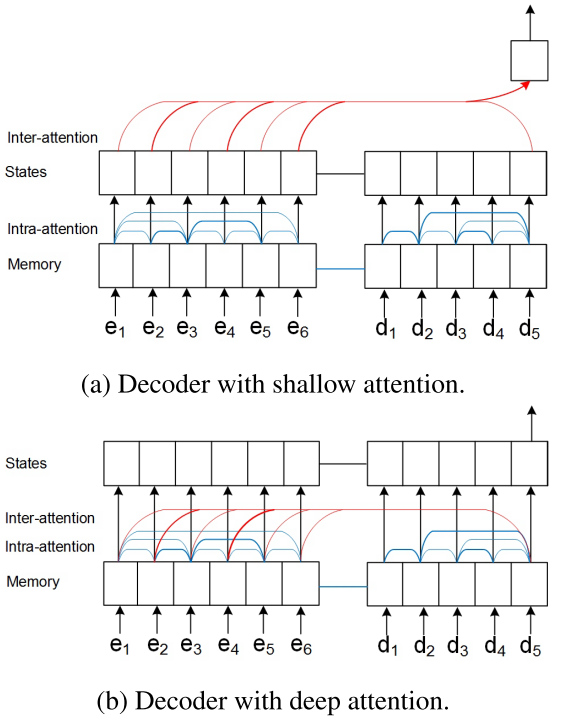
也就是目标的东西在更新的时候同时会考虑源语言的 并且这个attention 也是这样
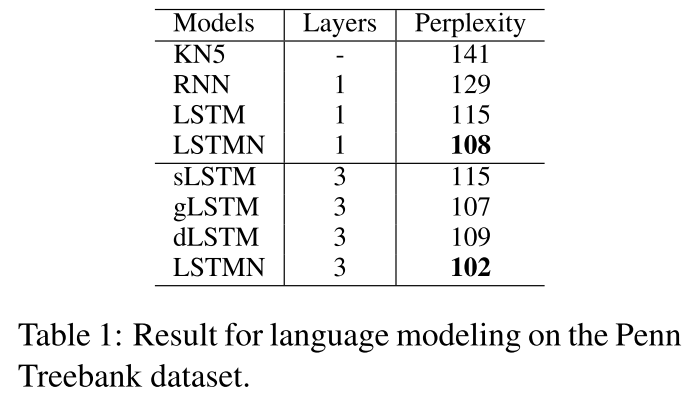
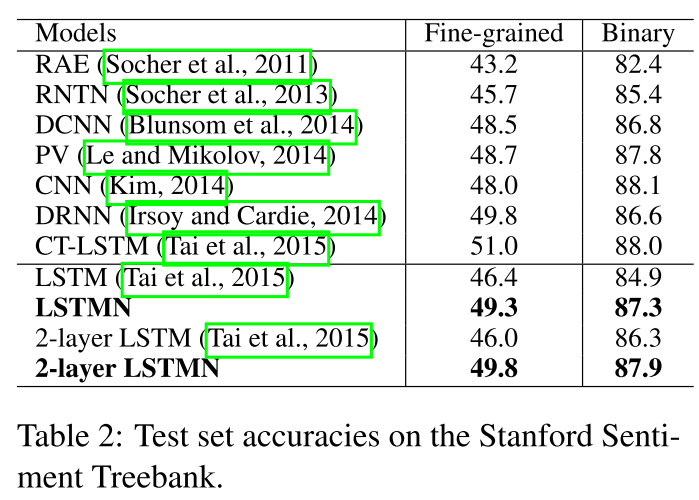
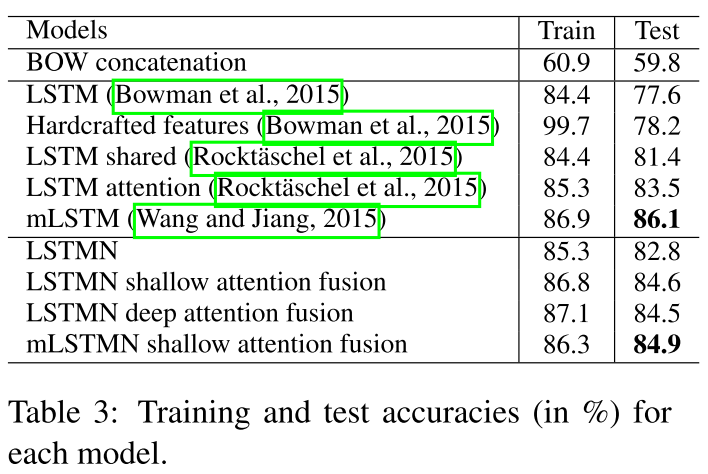
最后作者在 language model(困惑度) sentiment Analysis(socher的) 还有SNLI上面做的实验 效果不错
最后的代码是Torch的 有点看不懂
回复列表: