说实话这个文章不知道 放在那个目录下面 因为即是RNN的模型 又是语言里面的应用
===================================================================
讲的是LSTM的东西 但是加入了attention
出发点很简单 就是我们在表达一个句子或者一个序列的时候 往往只会注重某一部分 一个句子中只有一点点是有效的
但是我们的RNN则是每个字词都是相同的权重 但是这个不太好 但是往往我们的LSTM或者其他的只是在我们的生成的时候给一个权重 最后的所有的东西都是在Ht里面 并不是在将每个Xt加入的时候就考虑到它的权重和在全局中的应用 所以我们现在可以有一个显式的注重某个输入或者让某个输入不起作用的方法 所以这个东西就叫做奥卡姆剃刀原理
我们可以对比一下它和以前的LSTM的不同

可以看出来最大的不同就是在输入的时候我们就有一个门 来控制这个输入的大小 或者说这个句子的重要性 最后的 这g occam就可以当作我们的attention weight
然后我们的门的计算也和标准的一样
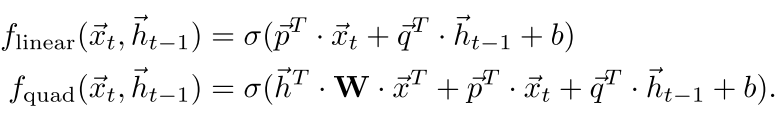
是线性或者双线性的
然后 我们为了让有些门比较小 有些门比较大 所以对其中的门加了一个L1约束
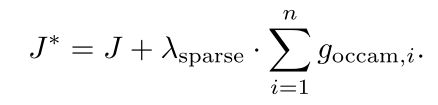
这个和普通的岭回归意思一样 就是要表达一个东西 我们不是用所有的特征 而是只是用其中的一部分就可以了 所以我们在attention的时候也是一样的原理
但是上面的这个式子有一个缺陷就是在训练的时候容易陷入到局部最优解 也就是所有的gates非常近 所以有一种新的训练策略,即逐步增大权值
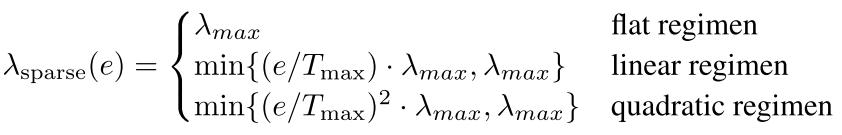
以上就是这个模型 可以看出来最后就是加了一个局部attention的作用
最后在 paraphrase detection情感分析和babi20上面做了实验
----
整体文章有点简单 模型描述的不太详细
回复列表: