这个是跟着上一篇LSTMN的 两个工作应该是同时展开的
================================================
这个工作首先提出 我们现在的东西有一个不足之处,那就是我们的所有的模型都不可解释,也就是我们的LSTM或者RNN根本都是不可以明明白白的说明为日什么好的原因,现在,为了让我们的历史信息能够显式的展现出来,我们现在定义了一个memory Network去解释这个模型
---
首先 标准的LSTM是这样
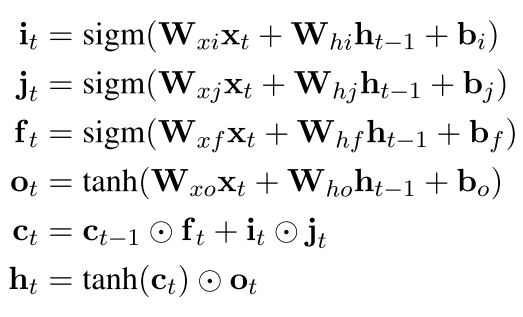
然后 我们可以看到每次更新的输入中都是上一次的ht-1和xt的一个结合 现在换了
我们假设当输入到第i个词的时候,我们将以前的若干个词表示成我们memory Network的一个东西
也就是 我们先将以前的若干个词 映射到两个矩阵上面去(M和C) 就是标准的MN里面那两个映射矩阵,其中一个是为了算权重,另一个是为了表达
我们的权重算的方法和以前的一样 就是这样
p t = softmax(M i*h t )
但是为了描述我们的顺序 作者加了一个东西
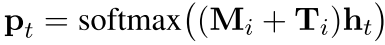
其中的 T可以表示为位置矩阵
然后就是表达 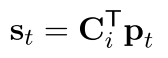
最后就是和隐层一起表示了输出,最开始的 MN里面用的是
g(s t , h t ) = s t + h t 也就是直接求和,但是这个有个不好就是不知道各个部分的权重,所以作者提出了一个东西和GRU类似
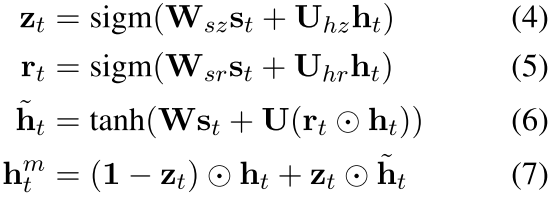
where z t is an update gate, r t is a reset gate. 所以最后的htm就是mn的输出 可以当作者这个词的隐层表达
用一个图表示就是这样
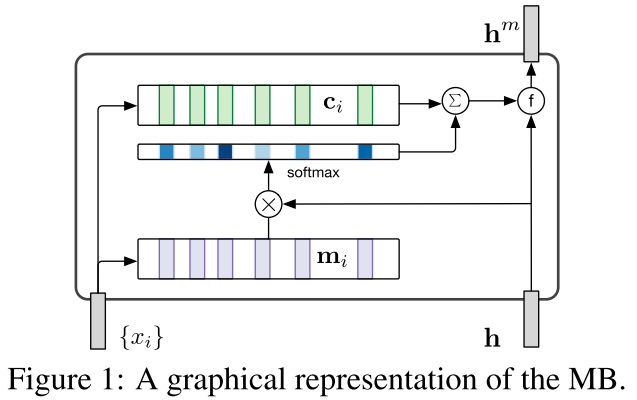
注意这个模型有两个表达,其中一个是传统的lstm 还有一个是hm 也就是mn的表达
回复列表: