今天又读了一篇文章,好像是发在AAAI16上面的,但是感觉好水,因为就是一个很工程的做法,没有模型
----------------------
作者说传统的QA中没有用到文本的东西(好奇怪),所以他自己把这个文本的东西加进去,以前用MLP的方法甚至还不如最简单的信息检索的方法效率高,所以作者在这里提出了好几种方法,并且将它们结合在一起。
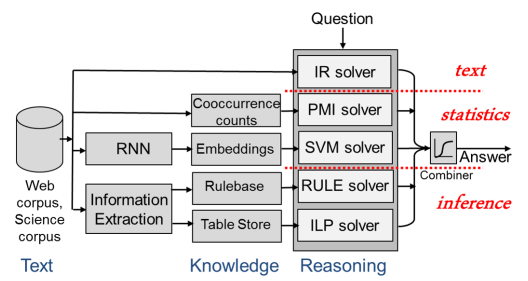
如图示:就是标准的几个模型,然后将各个部分组成在一起,然后我们可以看出来其实就是几个东西的组合,所以我们现在就把这个东西给明确化。
作者最后将这几个方法结合在一起的不是直接将他们的输出丢到一个classfier里面然后出结果,而是用了一个two step的方法
1)
对上面的五个sover 每一个sover其实都有很多特征,然后输出一个确信度,这个原始的确信度,但是这个确信度可能很大,影响其他的了,所以我们首先对四个答案或者所有的
候选答案做一个归一化。
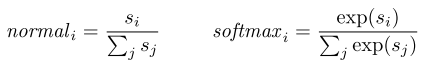
其中的j是所有候选答案的遍历,这样确信度就变成概率了。
然后,我们可以进行下一步
对于每个sover的每一个候选答案i 我们可以设置一个东西来表示他这个特征fs 我们把这个过程成为 calibrated
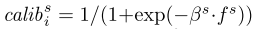
-------因为我们的每个sover不仅仅有输出的确信度,还有一系列的特征表示这个 所以对特征的组合也要归一化
然后对于某一个候选答案的确信度,我们就可以按下面的这个公式给出
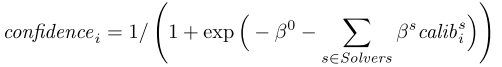
总之这个文章很一般,像是一个工程的做法
回复列表: