这篇文章是把现在有的东西全都灌了一个遍
其实我看这个的原因主要是想把那几个网络也给顺便看一下
======================================
首先,我们看一下maxout
就是在标准的卷积中,我们每一个卷积核都是线性的,这样没法cover住输入中多种多样的表达,所以 在我们网络的两层之间,我们加入一个max函数,去模拟一个任意的凸函数。
-------
传统的MLP两层之间就是直接有一个全链接就行了,假设输入是d维度的,输出(下一层隐含层节点个数)为n,但是现在为了将我们的maxout应用进去,那么我们以前的这个映射矩阵就是n*d维度的,现在我们把这个映射变成张量,变成n*d*k的张量,然后对于下一层的每一维,我们算出来k个这样的数之后然后取个最大值就行,所以我们的现在的表达就是
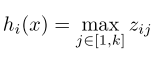 其中
其中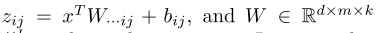
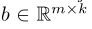
这样我们的这个层就可以逼近任意一个凸函数了,A single maxout unit can be interpreted as making a piecewise linear approximation to an arbitrary convex function.
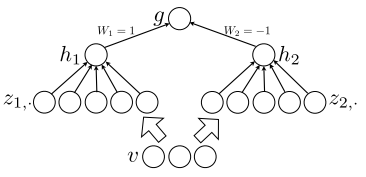
上面的这个就是隐层有两个节点,的maxout 其中k=5
原文中还证明了为什么这个东西可以逼近任意的凸函数
======================================
然后,我们看一下NIN :Network in Network(很可惜,这个model只能用在CNN里面)
首先,我们普通的CNN都是这样的 对于一个卷积核
The convolutional layers generate feature maps by linear convolutional filters followed by nonlinear activation functions (rectifier, sigmoid, tanh, etc.).
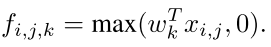
这个就是标准的东西 用的是RELU当作激活函数,而且k代表的是卷积核的个数,i,j是位置,我们最后的max pooling是要在i,j上面max的
However, representations that achieve good abstraction are generally highly non-linear functions of the input data. In conventional CNN, this might be compensated by utilizing an over-complete set of filters [6] to cover all variations of the latent concepts.
也就是为了描述数据中非常不线性的东西,只能是用多点线性核才行,但是这样是over-complete的 。However, having too many filters for a single concept imposes extra burden on the next layer, which needs to consider all combinations of variations from the previous layer
对比maxout 作者说 However, maxout network imposes the prior that instances of a latent concept lie within a convex set in the input space, which does not necessarily hold. It would be necessary to employ a more general function approximator when the distributions of the latent concepts are more complex.
也就是这个必须事先指定k 也就是那个在多少个核上面进行max的个数,而且最后求max是凸函数,对于更加复杂的函数的逼近肯能不行,所以作者提出了NIN
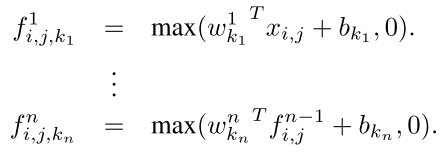
也就是 我这个卷积核算出来之后,不是直接输入到下一层,而是先经过一个MLP,为的是非线性,Here n is the number of layers in the multilayer perceptron. Rectified linear unit is used as the activation function in the multilayer perceptron.
对比的两个如下
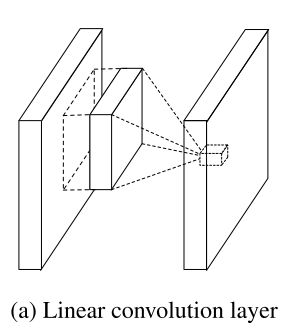
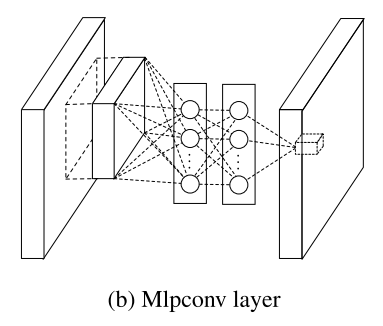
从图里面可能不太好看出来,其实标准的CNN就是一个卷积核弄出来好多然后pooling 现在是在多个卷积核上面进行MLP使之逼近任意的函数,这个真是牛
========================================================================
batch normalization
就是上一篇文章写的
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
现在 我们看看这篇文章主要讲的是什么,我们可以看到现在这个NIN用的是标准的RELU当作每一层的激活函数,但是这样有一个不好就是
However, the constant 0 will block the gradients flowing through the inactivated ReLUs and these ReLUs will not be updated during the training process.
所以 作者在这篇文章中采用maxout当作每一层的激活(注意NIN基本上是用在CNN里面的,但是Maxout是可以用在任何网络里面的)
但是当我们加入MAxout的时候,很多变量同时改变,所以我们需要克服这些,叫作co-adapting,所以我们有一个方法就是用batch normalization
作者提出的MIN Architecture 就是这样的一个网络
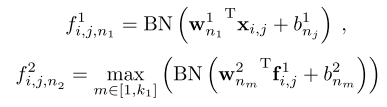
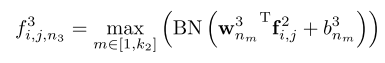
也就是每两层之间是NIN,但是激活用Maxout,然后每一层的输入是batch normalization后的
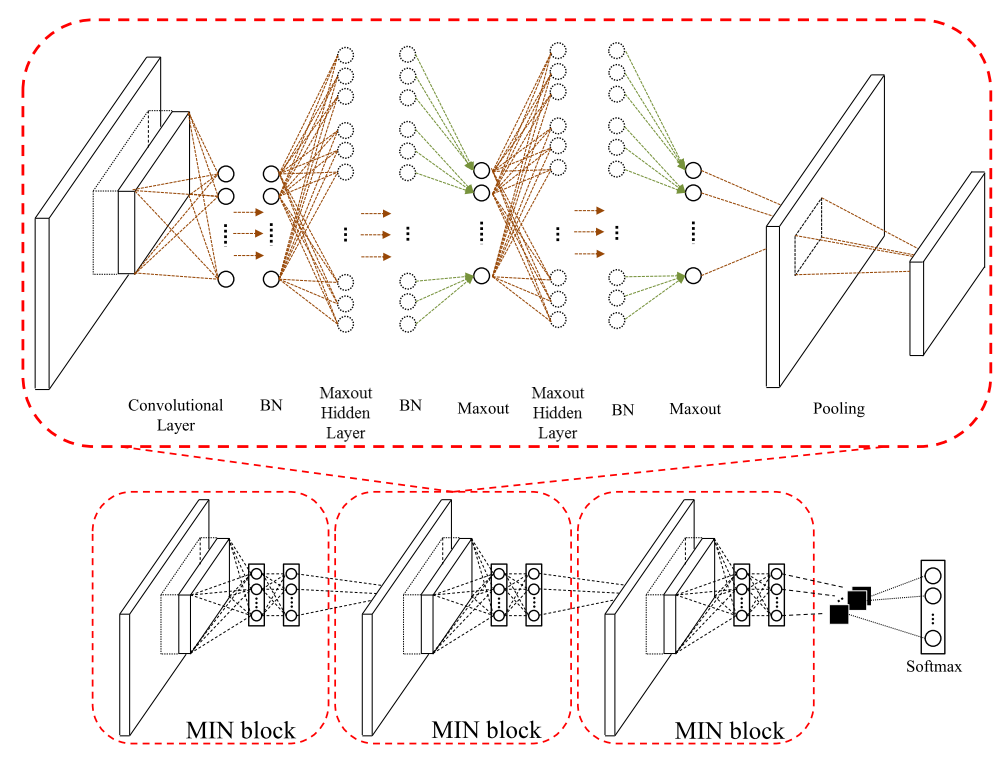
感觉还不错哈,就是不知道最后的总体效果到底怎么样。。。。
回复列表: