这下可算是找到一个牛逼的文章,一般般吧
======================================
首先在介绍这个之前先说一下课程学习(Curriculum Learning strategies):标准的课程学习就是从简单到难,
在最早开始的时候,先训练比较简单的样本,但是随着训练的深入,逐渐在比较难的样本上面采样集中一点,就是更加着重于复杂的样本
就是先是比较简单的样本,然后逐渐弄难的样本到我们的训练集里面,最后直到整个训练集都包含了。这种简单的样本有比较简单的根据具体任务确定的
比如在SVM中就是先训练确定两边的,然后逐渐往中间靠拢,但是这个比较简单的样本很难确定
我们在看看Hinton的知识蒸馏,(会在明天好好研究一下)
注意知识蒸馏是为了压缩的,或者说是简化网络的,要不然网络太复杂。
首先 我们用比较好的model训练出来一个非常牛叉的网络,然后称作这个网络是Teacher,然后我们开始降维,首先随机一个学生网络,这个学生网络有两个目标,
其中一个当然也是让他更拟合目标函数,还有一个目标就是和老师信号非常一致,
、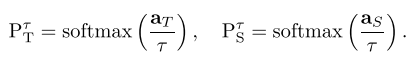
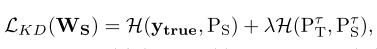
上面就是知识蒸馏的目标,其中h代表交叉熵
P T = softmax(a T ) where a T is the vector of teacher pre-softmax activations 就是我们的
可以看到,有一个at/t表示的是在softmax之前的表达,这个分母上面的t表示一个退火因子,也就是不是完全的拟合(那就和左边最后的输出一样了),而是和我们的这个教师的本身的表达一致。
但是KD也有一个不好的地方 Although we found the KD framework to achieve encouraging results even when student networks have slightly deeper architectures, as we increase the depth of the student network,KD training still suffers from the difficulty of optimizing deep nets
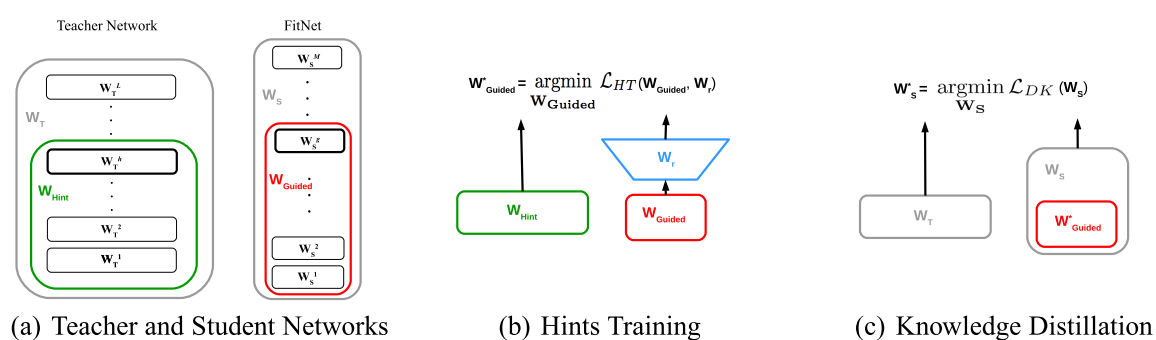
作者有两个定义,首先定义的是教师的隐含层中的某一层,叫作guided layer,然后学生的网络中的某一层,叫作hint layer,然后就是作者提出的一个就是让学生中的某一层能够学习到老师中的某一层,因为从输入到guided layer,教师网络已经有了一个函数(其实就是前向网络w1w2w3...)然后我们的目标就是让学生去mimic这个
所以作者提出的一个就是
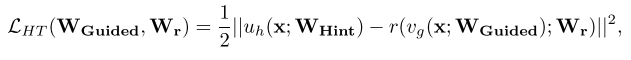
其中uh代表教师网络隐含层的输出,vg表示学生网络的输出。
然后因为这两个网络的输出可能不一致,所以就必须一致,这一个r就是一个regressor-回归的东西,就是一套参数把hint-layer映射到guided layer上面,然后最后让他们的MSE最小
现在我们还需要判断一下加入的这个hint layer和我们的这个guided layer的位置
Note that having hints is a form of regularization and thus, the pair hint/guided layer has to be chosen such that the student network is not over-regularized. The deeper we set the guided layer, the less flexibility we give to the network and, therefore, FitNets are more likely to suffer from over-regularization. In our case, we choose the hint to be the middle layer of the teacher network. Similarly, we choose the guided layer to be the middle layer of the student network.
也就是我们只需要在两个网络的中间加入就行了。
最后的总的表达就是下面这个
先用hint training将局部训练好,然后再总体上面KD
注意到teacher和student网络在图一上面的不同,可以看到我们的teacher是又矮又胖,然后student是又高又瘦
回复列表: