就是大规模进行词向量训练的一个玩玩(人家是谷歌,人家任性)
===========================================================
首先,作者将miklov的那两个东西称作:Skipgram Negative Sampling.(SGNG)
就是随机从背景里面选一个词然后让当前词和它的内积比较大(这样就相当于两个词比较接近)
levy和来斯惟从两个角度证明了这两个东西其实是一码事,就是在PMI的角度拟合两个矩阵
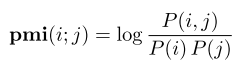
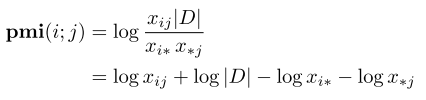
应该能看懂吧
然后就是设定两个矩阵,一个是当前词的词向量矩阵,还有一个是背景词的矩阵。
我们的目的其实就是
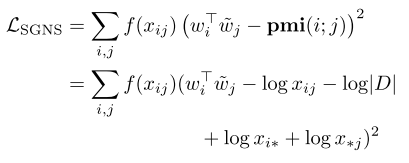
Due to the fact that SGNS slides a sampling window through the entire training corpus, a significant drawback of the algorithm is that it requires training time proportional to the size of the corpus.
也就是这个东西需要对整个的m*n(m是当前词个数,n是背景个数) 要是没有 pmi无穷小,惩罚相也就是无穷大
所以我们现在可以说这个是属于sliding windows
而Glove则完全不一样,他是完全从矩阵分解的角度,目标是这样一个 就是为了让那个co-occurence矩阵里面的东西尽可能的被上下两个矩阵拟合
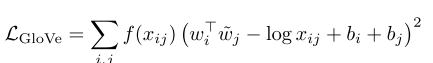
就是文档中出现的才被这个进行拟合,我们主要是看那些非0的元素,所以glvoe这种方法在作者看来
The negative sampling regime of SGNS ensures that the model does not place features near to one another in the embedding space whose co-occurrence isn’t observed in the corpus. This is distinctly different from GloVe, which trains only on the observed co-occurrence statistics. The GloVe model incurs no penalty for placing features near to one another whose co-occurrence has not been observed.
也就是不会对上下文不出现的词进行惩罚,这样做好像不太好,因为上下文不出现说明这两个词非常不一样 应该内积很小
现在我们看看作者的这一个模型
对于可以观察到的内容,我们可以看到有下面这样的目标
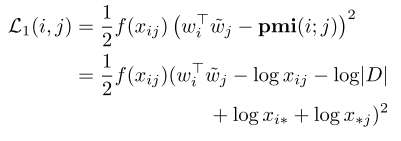
而对于文档中没有观察到的东西,我们有下面这样的目标
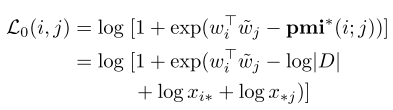
Here, pmi∗refers to the smoothed PMI computationwhere x ij ’s actual count of 0 is replaced with 1.就是用1代替0
做出上面这个假设的原因是下面这样的一个动机
Treating
x ij as a sample, we can ask: how significant is it that its
observed value is zero? If the two features i and j are rare,
their co-occurrence could plausibly have gone unobserved
due to the fact that we simply haven’t seen enough data.
On the other hand, if features i and j are common, this
is less likely: it becomes significant that a co-occurrence
hasn’t been observed, so perhaps we ought to consider that
the features are truly anti-correlated. In either case, we
certainly don’t want the model to over-estimate the PMI
between features, and so we can encourage the model to
respect an upper bound on its PMI estimate wiTw j .
就是如果xi和xj都很小,那么可能是数据中确实咩有这两个东西,所以不让有,这样wiwj还是可以非常大
但是当xi和xj都很大,都经常出现,那么这就说明他两个确实是不经常在一起,绝对是不在一起的,所以应该让他俩的内积小
-----------------
作者最后说了一个关于glove的实验结论
Notably, Swivel performs better than SGNS at all word frequencies, and better than GloVe on all but the most frequent words. GloVe under-performs SGNS on rare words, but begins to out-perform SGNS as the word frequency increases.We hypothesize that GloVe is fitting the common words at the expense of rare ones.
回复列表: