这个是IBM waston的工作,主要就是在CBtest和herman的那个数据集上面做
=================================================================================
属于完形填空
================================================================================
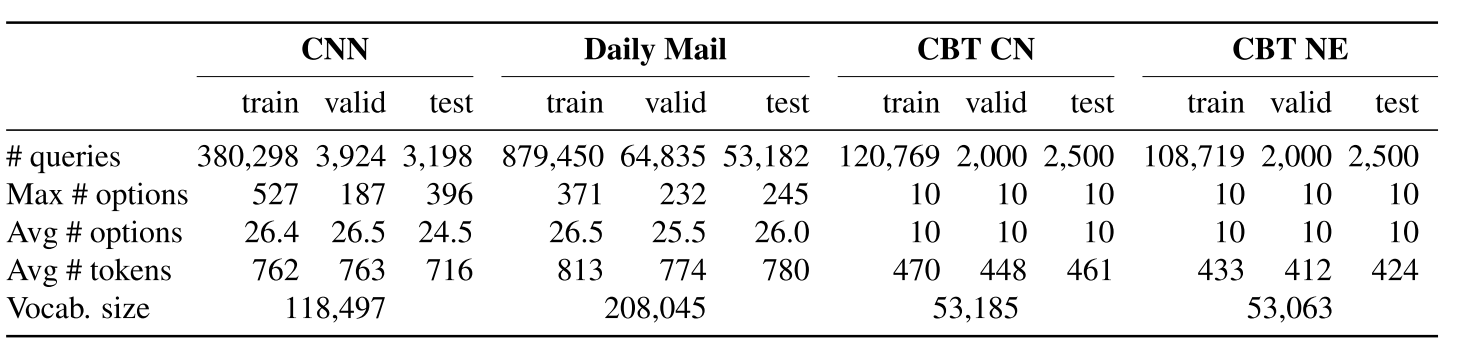
那几个数据集的参数如上
数据集的地址为:
The CNN and Daily Mail datasets are available at
https://github.com/deepmind/rc-data
The CBT dataset is available at
http://www.thespermwhale.com/jaseweston/babi/CBTest.tgz
=====================
主要思想就是
先用RNN(GRU)算出每一个文档中的单词的表示(正向和逆向的拼接在一起),然后把问题表示成一个向量。最后它假设答案肯定都在文章中出现过,所以每一个词的表示和问题的表示求一个余弦距离,最后将各个词的余弦距离(一个词可能出现多遍)加和(题目中的sum) 就变成了最后的结果
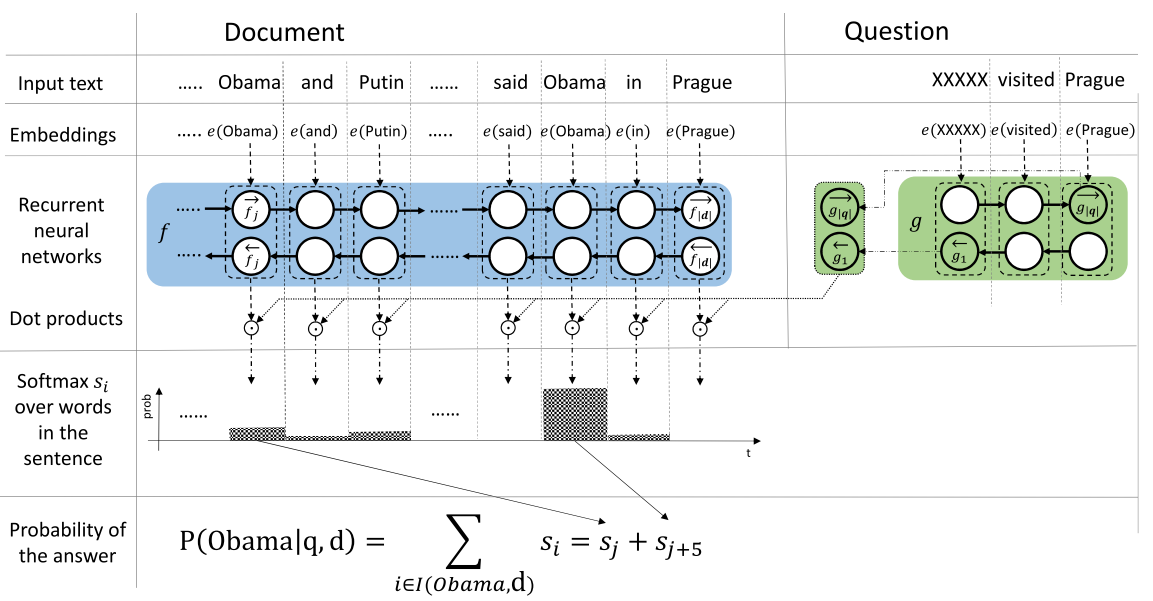
作者最后的evaluation method非常好 就是下面的这个例子
The ensemble models were chosen either as the top
70% of all trained models or using the following al-
gorithm: We started with the best performing model
according to validation performance. Then in each step
we tried adding the best performing model that had not
been previously tried. We kept it in the ensemble if it
did improve its validation performance and discarded
it otherwise. This way we gradually tried each model
once. We call the resulting model a greedy ensemble.
就是第一次先是找一个最好的model 然后逐渐往里面加 每次加的model要是能让在development上面的效果好,就继续,要是不好 就不加进去
=======================================================
水平非常低的一篇文章
回复列表: