这个是说在RNN里面如何应用drop out
===================================思路很清晰 跟我的ACL的分析问题方法很像===============================================
首先看dropout
以前是直接一个输入和一个输出之间 y=f(wx)就行了 w是权值矩阵 现在换了一个
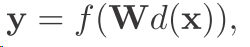
其中
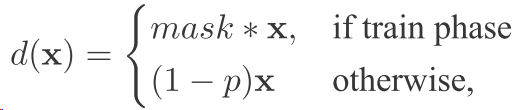
也就是我们的dropout的核心 就是在训练的时候随机mask一些目标,不训练它 然后误差就通过其他的就节点传递了 但是在测试的时候我们要对每个节点乘一个这样的系数表示
最后的输出 因为dropout后其他的节点相当于训练传播的误差增大 例如本来有100个隐层节点,但是现在dropout了50% 每次也就有50个节点 这50个节点就要干100个节点干的活 所以能力也是这100个节点的 但是最后在测试的时候 大家又都回来了 所以每个节点的 能力还是要减半
==============================================================
以前的dropout在rnn中一般都是这样
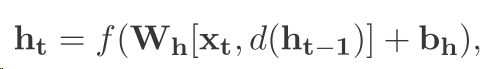
也就是每次都把上一个隐层给drop一点 但是这样回失去long term的信息 稍后细谈
LSTM:
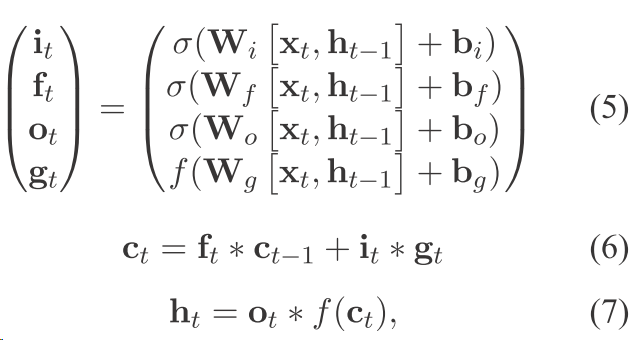
然后这一篇文章是这样dropout的
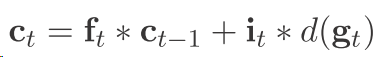
但是以前的文章都是这样dropout
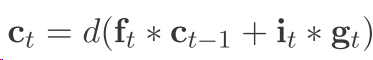
这样非常不好
1)以前的这种dropout 是会失去一些很有用的信息的 因为你这样肯定是最后直接在某个ct上面为0 这和最后在输出节点 也就是在输出层(公式7)把ft的某一维设置为0没什么区别么
2)
我们用数学的表达来说一下 假设现在这个LSTM内部所有门的更新都是1 那么也就是
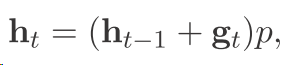
然后我们往回推
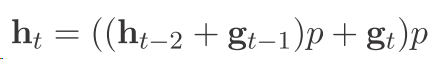
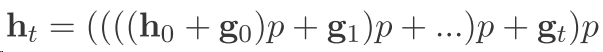
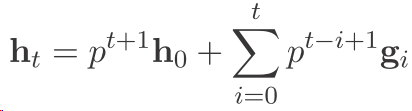
可以看到以前的东西都没有了 并且以前的信息存的很少
而作者提出的 这个方法 有一个好处就是
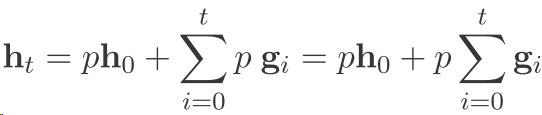
可以看到这样把以前的信息都给整理了下来
=========================================
实验代码
回复列表: