这个是许家铭师兄的一个文章 发表在IJCAI2016
=====================
为什么要看text hashing 哈哈
=====================
文本哈希的任务主要是把一个文本映射到一个低维的,0 1 表示的空间中去,这样会使搜索更加快速 好像很有道理的样子
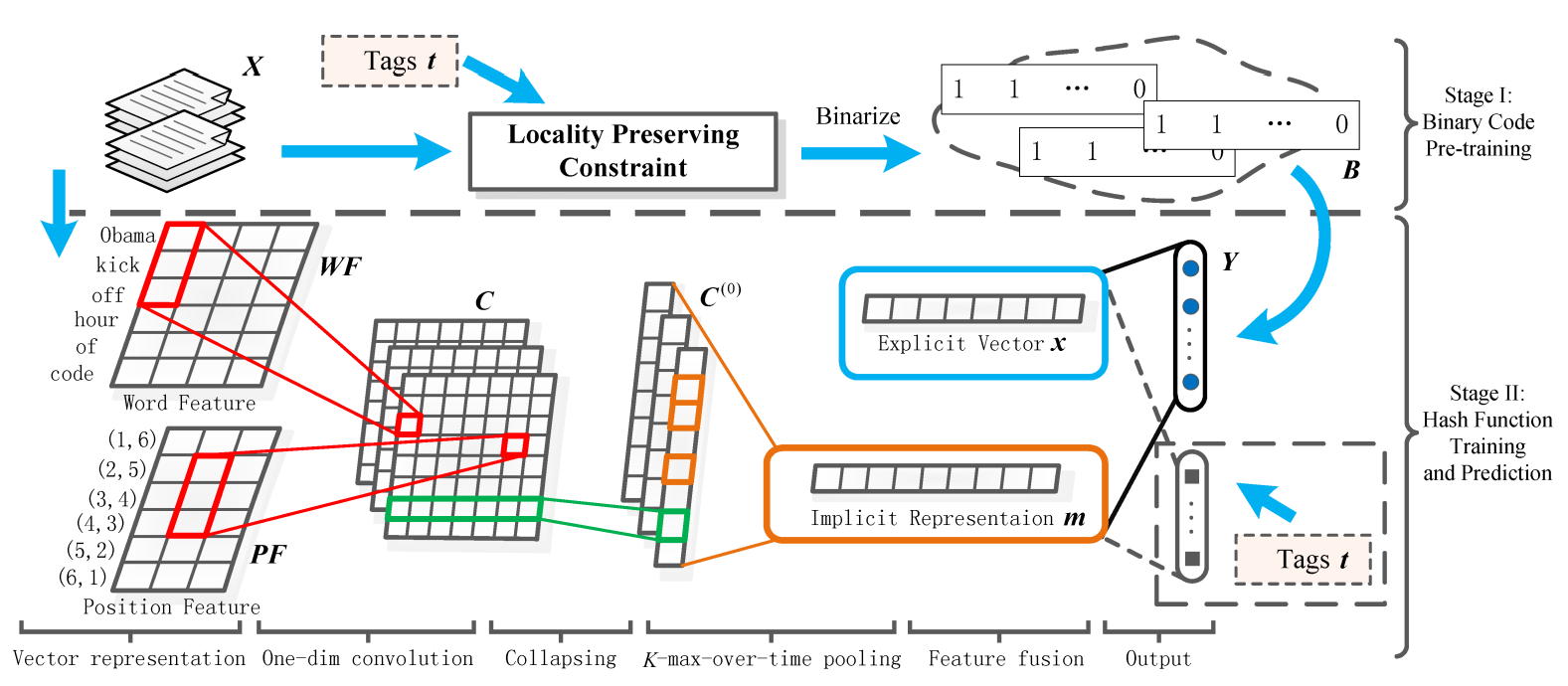
上面这个是文章的主要结构,记住 右上角的B是已经学习出来的致密的0 1 表示 具体怎么得到的 其实也不清楚 反正这个B就是最后我们这个框架表示完之后的一个目标,
B一般是这样获得的
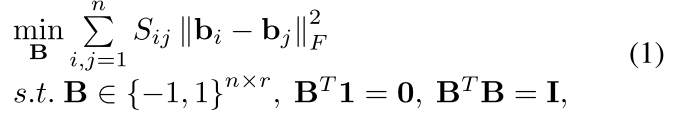
现在有很多标准的方法可以得到这个B 就是谱聚类那一套
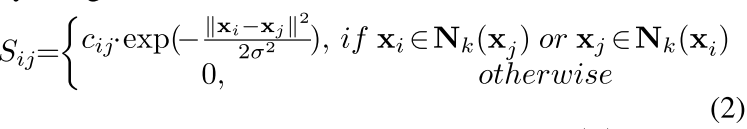
这个是相似度 右边的表示最近邻 我们看到这个东西其实是先预处理一下然后可以做了
===============================好了 他们现在已经有了一套训练集了 训练的目标就是这个B 但是在实际应用的时候 我们可没有最近邻 所以还是得自己建模一套使之很好的表示
然后就是看上图的用CNN表示 把位置信息也考虑的进去 然后最后出来一个Explicit vector 说是来拟合最终的这个致密的B
好像很简单的样子
文章用的数据集在这
代码师兄也没公布~~~~~~
回复列表: