这个是介绍现在文本抽取的工作
------------------------------------------------------
传统上 自动文摘有两种方法,一种是extractive 还有一种是generative
第一种需要的数据量比较少,但是只能从原文中抽取出来比较有用的句子,而且都是直接是句子,这种方法虽然简单,但是不足也非常明显。
第二种生成式的就很好了,在现在deep learning大行其道的今天,先把document表示成一个向量,然后再不断的解码。这个好简单啊
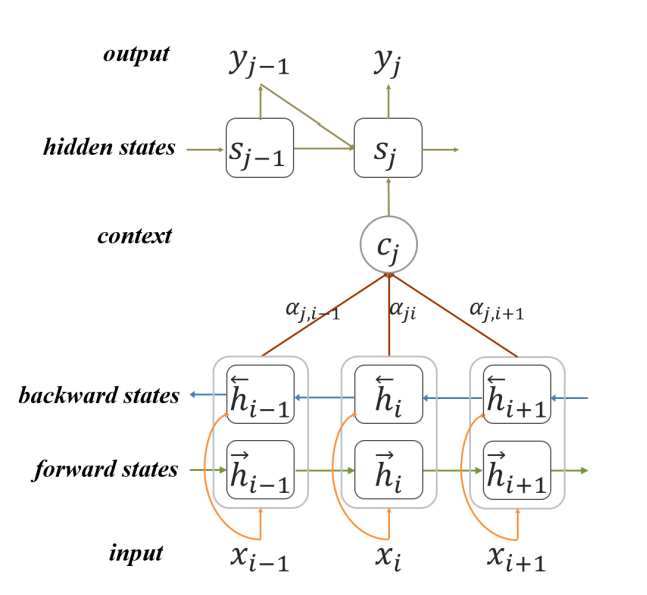
一般把这种抽取叫作 neural headline generation (NHG)
但是现在的NHG有很大的不足,就是训练目标是MLE 也就是极大似然估计,但是这种方法往往只考虑的是单字级别的优化,但是我们评估的是整体的相似度,所以这种方案不好。
我们细细来说
以前的主要是这样
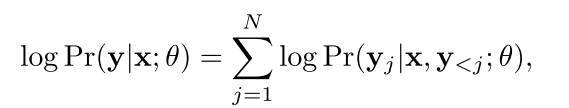
就是训练目标是每个字根据上一个字然后生成新的字的概率,然后最后整个句子的概率相乘,在训练的时候,就是x也给你了y(headline)也给你了然后让你优化目标的概率,这个好可爱,但是实际中我们不应该这样的来优化,而是用整个句子的信息来优化。
所以作者提出了最小风险训练 Minimum Risk Training
思想就是这样:我们首先根据现在的这套参数直接生成一个我们的headline y' 然后定义我们的这个整个句子和真正的目标的句子的损失函数或者loss如下:
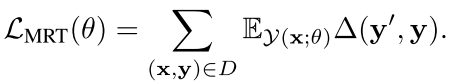
也就是当前这个y’和真正的y的距离(
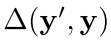
)在y'的期望,we define Y(x; θ) as the set of all possible headlines generated by NHG with parameters θ.
当我们的这个x很容易生成y'(在我们的模型参数下),但是y'和实际的y差了很多,所以这个差别就大,我们就应该更狠的惩罚。
但是这个期望很难算,因为我们想知道这个x生成这个y的概率,不可能只是用编码最后得到的概率来求,而是给定一个系列然后看看
现在我们不能求得全部的y(x;θ),所以缩小范围,用另一个代替:现在的目标函数变成
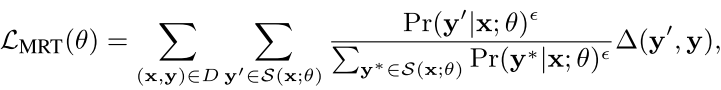
其中伊普西隆是平滑因子,一般很小
但是两个句子的语义差别一般用ROUGE 这个是衡量两个句子语义相似度的一个东西,我们可以用下面的这个公式来表示两个句子的语义相似度:
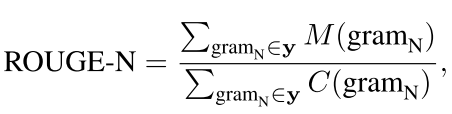
M(gramN) is the number of n-grams matched between y 0 and y, and C(gramN) is the total number of n-grams in y.
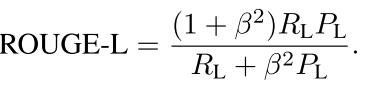
其中的Rl和Pl都是和句子长度有关的信息
需要说明的是最后的
最后作者选择的那个s(x;theata)是取前一百个最大的可能性的
--------------------------------------------------
其实我感觉作者可以更好的一种方案,就是直接是这个句子的生成的概率当作前面的,然后后面的也不用什么rouge了,直接用RTE或者用paraphrase detecting做的结果就行,也不用什么ROUGE了
回复列表: