这个还是hashing一类的
================================
本文采用的还是有监督的hashing
记住一点,也就是hashing是要在数据降维,数据快速搜索的地方用到的
首先看看作者的方法,首先对于我们的每个样本点,假设它是d维的,然后我们可以将每一个样本点都打一个标签,这个标签就是这个样本的类别,然后这些样本点可以当作我们分类的标准,然后对于每一个这样的点,我们假设要把他映射到m维的汉明空间,然后我们可以得到这样一个映射
![]()
也就是我们每一个汉明空间的点都是以前的d维空间映射过来的,这个方法作者是想每一个点都是由以前的东西弄来的,所以我感觉计算量肯定特别复杂。
但是现在我们要注意,在这里作者其实映射到的空间不是 0 1而是 -1 1
现在我们可以在汉明空间计算两个样本的相似度,如下:
![]()
这个数越大说明越相似
然后我们已经知道了每个样本点的标签也就是 yij,所以现在的训练目标可以如下:
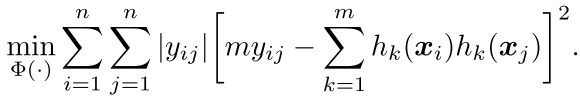
现在我们还没有具体的说到底怎么去得到这个hk(x) 也就是如何得到一个样本点的code
但是 我们的样本点的code 必须是满足上面的这个形式 也就是一定要使上面的这个最小,也就是我们的hk(x)可以提前学出来。
后面我会讲到许佳铭师兄是怎么办到这个的
然后,在这个里面 我们可以用各种方法得到这个hk(x) jacoxu同学是用的cnn得到的,但是这篇文章用的是决策树:如下
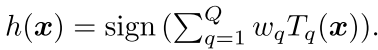
其中Q是决策树的个数,其中的T表示的是我们每个树都是 -1 1 的输出
然后现在我们就要看看怎么去优化了。
一般采用的是 Two-Step Hashing (TSH)
也就是先优化hk(x)把这个得到,得到了这个code之后我们就可以做机器学习的任务用各种方法得到它了。
这个是hashing的核心
首先,我们继续看看本篇作者的工作的核心。
对于上面的这个,我们首先优化第一步,也就是得到code,现在是我们可以做一个表示
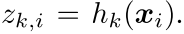
然后,我们的目标就是这样
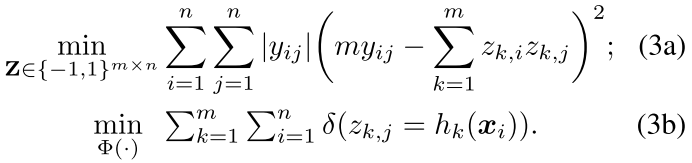
其中3(a)是我们的code学习过程,然后3(b)是我们的拟合过程
然后我们可以对于其中的第一步:Binary code inference.构建下面的步骤:
每次只优化一个点,也就是zki中的一个点
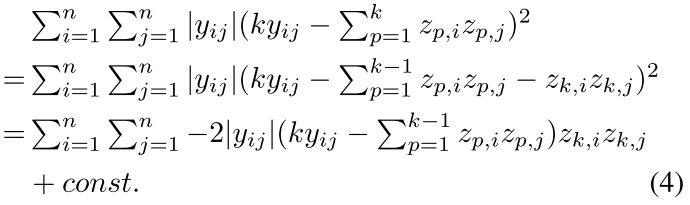
上面的公式需要用到(a+b)^2这个最基本的公式
注意除了zk其他都是定制,而且zk^2=1
现在其实就是优化上面公式的第三行
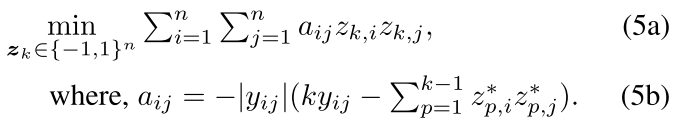
Here z∗denotes a binary code in previous bits.
注意在作者的方法中,我们每次的更新的是第k个以前的,而不是m个点中除了这个点之外的,作者说这样做有助于整体的效果提升
但是我们看到5(a)还是有n*n个要优化,这个还是有点大,作者又一次选择拆分,我们将训练集(n)个点分成几个block,然后每个block的这样的优化。
首先我们的训练集可以分为好几个block然后优化目标是这个block内部的东西
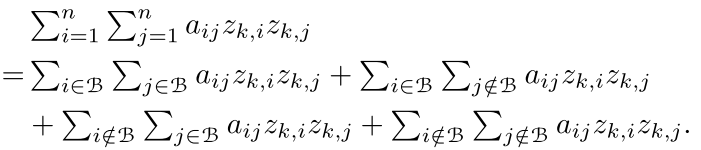
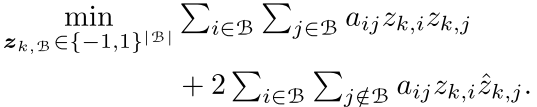
作者构造block的方法就是随机采样,然后看看欧式距离是否相近。然后看看是否采集到了足够的点,然后就停止
然后对于上面的式子3(b) Learning boosted trees as hash functions.作者也提出了一种方法,不是那种非常硬的学习01,而是一种指数族的目标函数,也就是下面的这个方案。
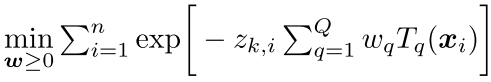
最后再用Adaboost来搞定 非常好
最后这个工作就结束了 是不是很有意思啊 这个工作的主要优势就是在高维大数据量上面取得了很快的训练过程
----------------------------
我们看看jacoxu的工作(IJCAI2016)
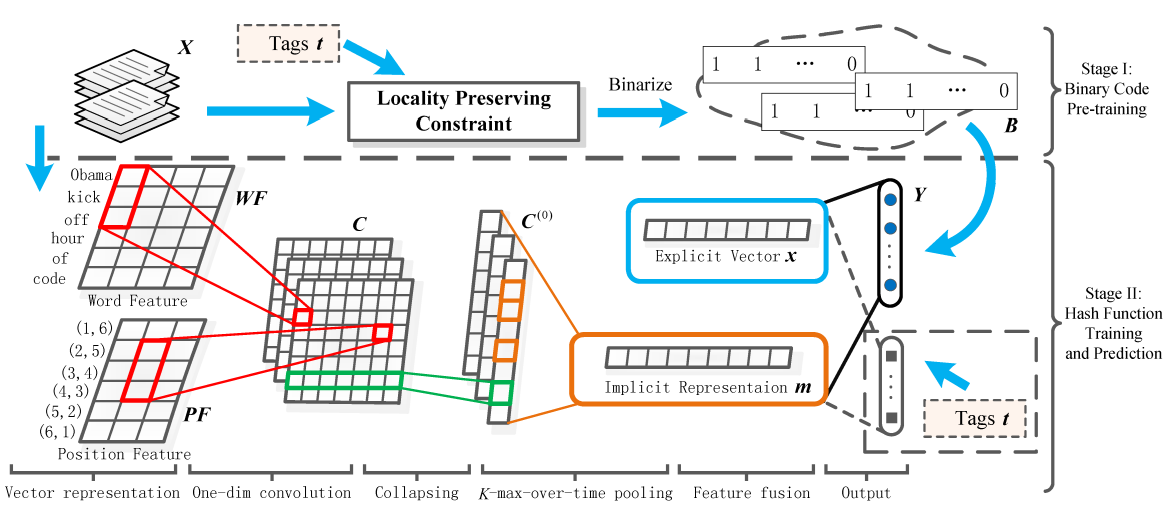
可以看到jaco的工作也是分成两步,第一步就是先把二进制的code得到,第二步然后就开始好好的搞自己的事情了,第二步也就是作者的把相同的聚在一起的工作
jaco在第一步采取的是前人的工作:
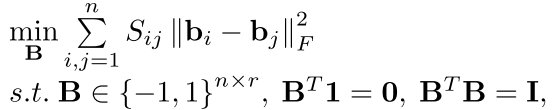
i,j都是训练集的样本点。然后我们可以看到
我们的目标有
and the r-dimensional real-valued vectors ˜B can be learned from Laplacian Eigenmap. Then, we get the binary code B via the media vector m = median(˜B).
也就是可以通过谱聚类那边的一套得到这个二进制码,这个相似度矩阵可以这样的构造
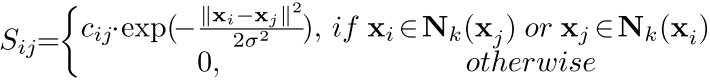
然后在第二步CNN就是为了学习这个二进制代码的,有很多学习方法
最后的cnn输出,要加上一个logistic回归的东西
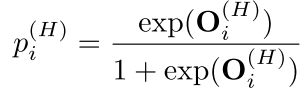
这样就可以使之更靠近两边了
--------------------刚才这个是IJCAI15的工作,现在其实还有一个IJCAI16的工作,是南京大学李武军老师的工作------------------
李武军老师的这个工作名字叫做:《Feature Learning based Deep Supervised Hashing with Pairwise Labels》
主要就是用深度学习的模型(其实还是CNN)来产生特征,并且和最后的label在一个框架下面训练 ,也就是code inference和表示放在一起
模型的总体架构如下:
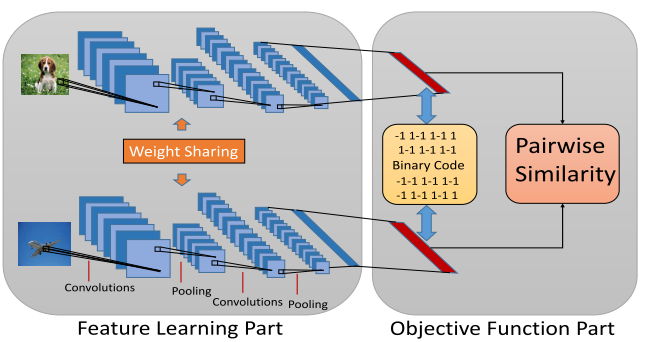
其实就是每次进来两个样本,然后用cnn把他们表示,然后还有一个pairwise的相似度用来看两个样本是不是非常相近,这种相近我们可以看作是预先知道的资源
首先CNN就不细讲了,因为这个文章主要做的是在图像上面的,所以参数如下:

可以看到其实参数还是非常多的
然后对于训练目标,我们主要是想得到一个b,也就是 -1 1的值作者用了这个方法
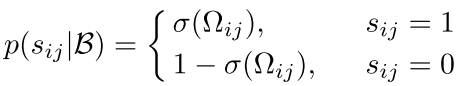
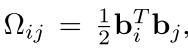
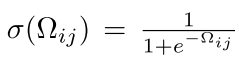
所以现在我们的优化目标就变成了下面的这个目标函数:
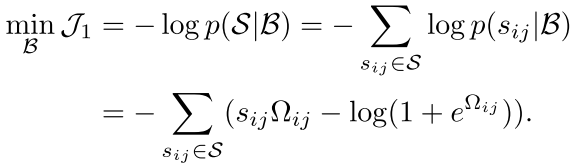
可以看到这个公式里面主要的还是优化
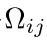
但是这个东西特别难优化,因为是01的值
现在作者就做了一点简单的处理,不是确定性的就是01了 而是把01当作一个优化目标
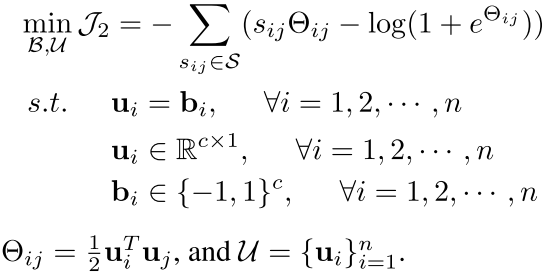
为了优化上面的目标,我们可以这样
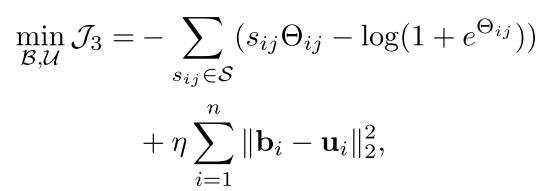
这样又是一个简单的逼近,后面我们会看到怎么得到这个b
===========
首先我们的东西是最后要优化的目标,我们在cnn之后,把这个cnn的输出转到汉明空间是这样的
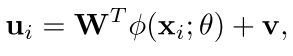
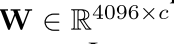
然后我们可以看到其实就是把cnn的输出给映射到一个新的空间里面
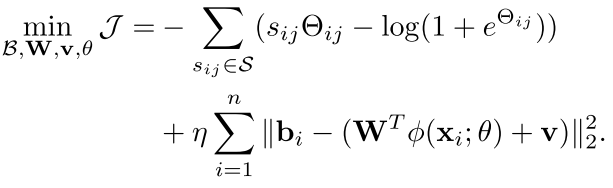
现在的优化目标就变成end-to-end的了,而且b也非常简单,直接就是
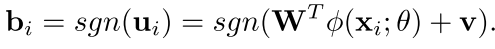
这个是因为作者每次只优化一部分,优化这一部分的时候另一部分是fix的,哈哈 真棒
求导什么的就不说了 自己看吧
回复列表: