这个文章虽然是在情感分析里面做的,但是结合了NLP,我感觉很精彩
=======================
首先sentiment Analysis结合了两部分,以前只是有opinion 的mining过程,就是看看这个opinion 是不是好的
但是现在加入了aspect的检测,也就是观点或者说属性。
一个产品的 观点 比如对于手机来说,就是 屏幕啊 电量啊什么的 opinion 就是指 好啊 耐用啊什么的 这个是情感分析里面的两个部分,我们应该分别对待
现在作者把这个当成一个序列标注的过程,也就是在我么的一句话来了,我们要看看是情感点还是aspect的 所以就是序列标注任务
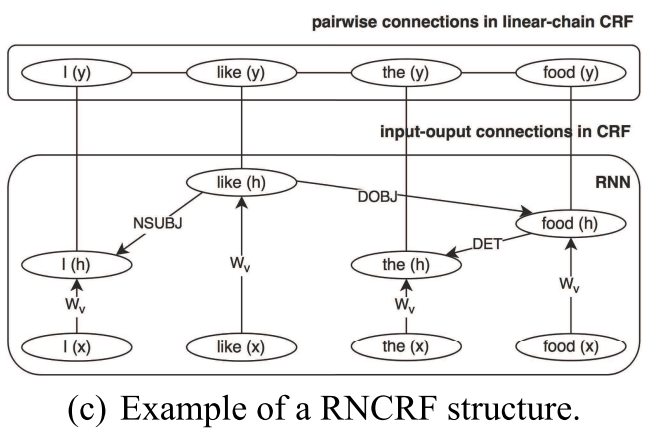
首先是先把一个句子 依靠依存句法树用recursive neural Network表示出来 可以看到是这个样子
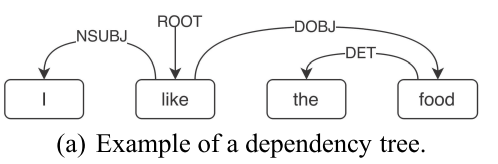
然后 根据以前的那种网络结构 我们
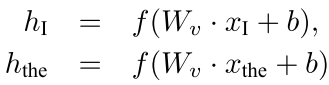
就是一个词的embedding 组成了一个词的隐层的表示 只要这个词是叶子节点
但是对于一个非叶子节点来说,我们可以这样的构造它的隐层状态
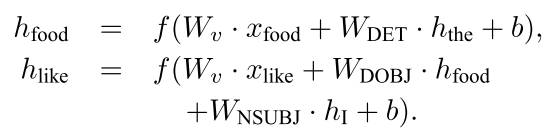
也就是各个子节点的隐层权重是各个隐层节点的表示和那个依存关系的权值矩阵(只有几种)的表示只和
通用的表示就是:
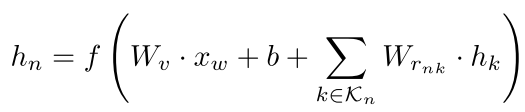
where K n denotes the set of children of node n, r nk denotes the dependency relation between node n and its child node k,
现在我们看看这个CRF是怎么回事
Here h i is a matrix with columns of hidden vectors {h i1, h i2, ..., h in i }to represent a sequence of words {w i1, w i2, ..., w in i } in a sentence s i . The model computes a structured output y i ={y i1, y i2, ..., y in i } ∈ Y, where Y is a set of possible combinations of labels in label set L. The entire structure can be represented by an undirected graph G = (V, E) with cliques c∈C. In a linear-chain CRF, which is employed in this paper, there are two different cliques: unary clique (U) representing input-output connection, pairwise clique (P) representing adjacent output connection,
由于前一段时间刚刚写过CRF的介绍,我现在就不细说了
但是还是把公式放在这吧
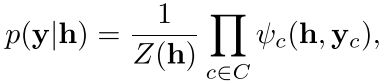
ψ c (h, y c ) is the potential of clique c, computed as
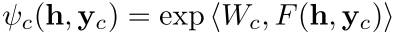
现在 我们选一个窗口来刻画这个关系
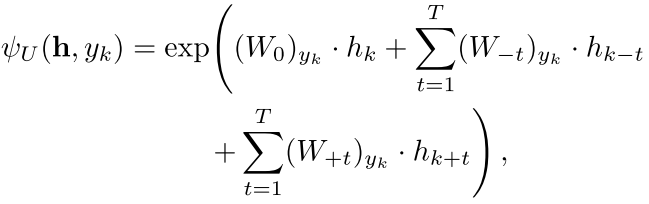
其中个窗口大小就是2T+1(左右各T个,中间一个)
W0, W+t and W− t are weight matrices of the CRF for the current position, the t-th position to the right, and the t-th position to the left within context window
注意其中的下标yk指的是W0矩阵中的一行,也就是得出来其实还是一个数
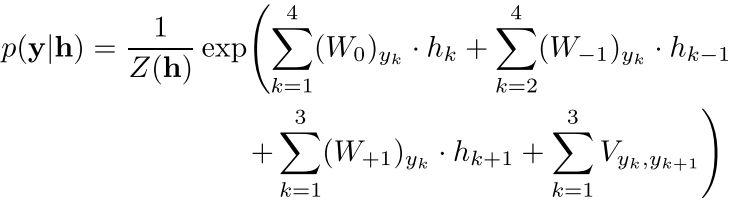
但是最后没有说怎么inference,只说了怎么求导参数,一般般吧
=====================================
The most important advantage of RNCRF is the ability to learn the underlying dual propagation between aspect and opinion terms from the tree structure itself.
在这个文章中作者说最好的部分就是可以考虑从aspect到opinion 的双向的影响
因为根据RNN,两个词之间的关系可以在依存句法树上面很好的表示出来,也就是aspect和opinion肯定会有一个边将它们链接起来。
这样在crf中可以刻画很远的东西,并且是在向量空间里面将它们表示在一起的
回复列表: