好么 这玩意一下子就赶紧去3千万个训练样本,但是都是基于事实性质的
==============================================================
首先,所有的训练集都是simpleQuestion上面的,那个上面有很多基于freebase的数据集,也就是freebase的三元组,然后抽掉一个补全另外一个。由这个东西生成一个句子,也就是问句。
现在作者怎么做呢?就是把三元组用向量表示用transE训练一下,然后将这三元组当成翻译里面源语言的表达,然后在解码这个 ,就是传统的NTM
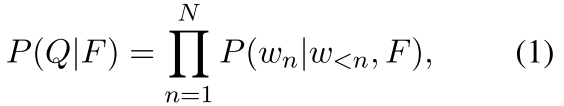
只不过这里它的decoder比较牛逼
来来来 看看他是怎么弄的
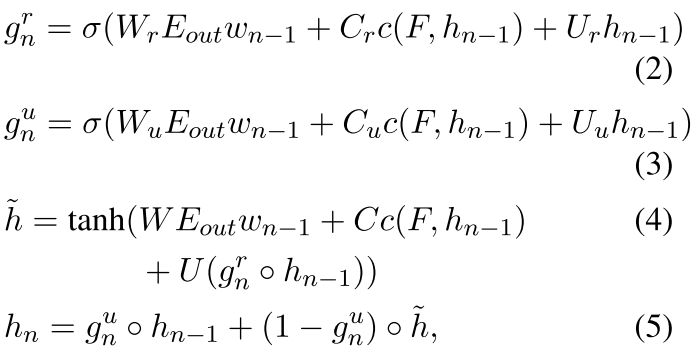
其中的E都是embedding matrix 因为w都是一个词的位置
c(F, hn−1) 是表示的上下文的向量,可以这样计算
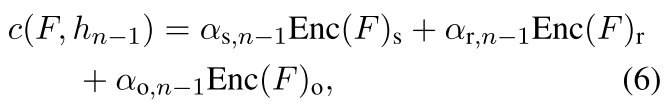
也就是 是由原来triple的三个依权值进行处理,其中αs,n−1, αr,n−1, αr,n−1 are real-valuedscalars, which weigh the contribution of the subject, relationship and object representations,在计算的时候是是Enc(F)和前一个矩阵的隐含层拼到一块然后直接映射到一个三维的输出然后sigmoid一下就是最后这三个attention值 呵呵呵
其他的东西就非常ad-hoc了 包括怎么样选取三元组 还有在训练的时候把triple的名词代替成一个placeholder等等
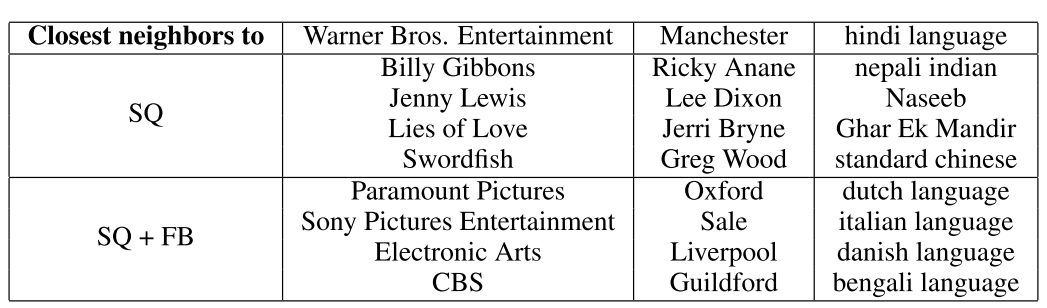
这个图是加了不同的embedding的效果,因为SQ(simplequetion)也有三元组,但是太小,加了FB的 效果好多了

这个模型的效果最后可以看到非常好
除了BLEU 还有一种评价方法叫做METEOR
([Banerjee and Lavie2005] Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the ACL workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, volume 29,pages 65–72.)
回复列表: