这个是做自动文摘的Extractive的方法。
======
我感觉这个可能最后的结果没有作者说的那么好
==========
作者在这个工作中的主要做法就是先从一个document中提取出有用的句子,然后再从这些句子中提取出关键的那个summary

这个就是标准的一个自动文摘的例子
首先看看作者的数据集是怎么构造的:
sentence提取的过程是这样的,为了找到有意义的sentence在一个文章之中,我们比较每一个文章中的句子和这个文章中abstract的语义相似度,这种计算方法是依靠以前的一些方法:[Woodsend and Lapata2010] Kristian Woodsend and Mirella Lapata. 2010. Automatic generation of story highlights. In Proceedings of the 48th ACL, pages 565–574, Uppsala, Sweden.
作者在这里也是用了一些rule based system 来做的 可能有点low
然后看看word是怎么提取出来的:we examine the lexical overlap between the highlights and the news article.,当所有的highlight的文字和文档中的文字重合的时候,那么这个文档就可以被当作有效的(因为这篇文章的方法是extraction,所以所有的文字必须在文档中出现过)
we obtained a word extraction dataset containing 170K articles, again from the DailyMail.
然后看看作者怎么构建模型的:
对于文档的建模,首先作者是用CNN把每个句子的语义表示出来,为什么要用CNN呢?
Firstly, CNNs can be trained effectively (without any long-term dependencies in the model) and secondly, they have been successfully used for sentence-level classification tasks such as sentiment analysis (Kim, 2014)
具体如下图:
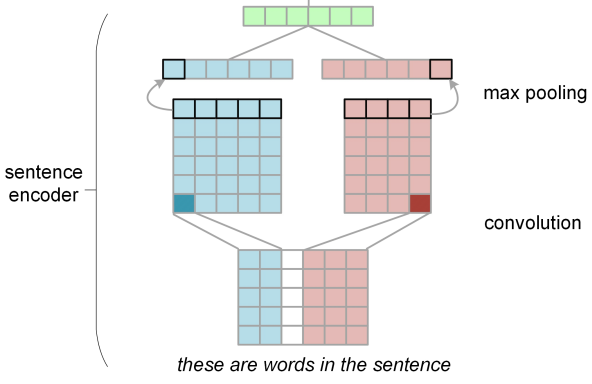
然后现在得到了每个句子的语义,然后用recurrent nn把这些句子的语义构建出来。作者在这里用的是LSTMs
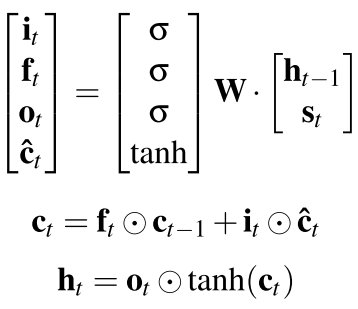
注意st是CNN得到的句子的语义,但是在文档中,它的语义是ht
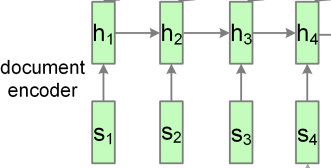
好了 现在文档中每个的语义有了,整体的语义也有了(max-pooling ht或者取最后一个ht)
我们首先可以考虑如何找出文档中有用的句子:
The extractor is another recurrent neural network that labels sentences sequentially
对于这个sentence extractor 为了使最后的得到的句子之间的冗余度最小,所以作者在这里加了一点attention 也就是必须和以前的选择的句子要保持一致,所以公式是这样的:
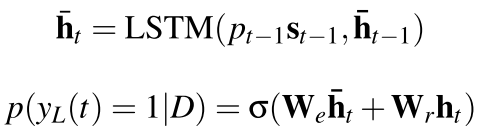
也就是,每次输入还是以前(CNN)的句子的表达st 然后和当前的隐层(这个是另一个RLSTM了),然后选择生成了之后,最后判断这个ht是不是应该被生成出来,要看的是
当前extractor的隐层表达(h_t)还有以前的这个这个隐层的表达ht
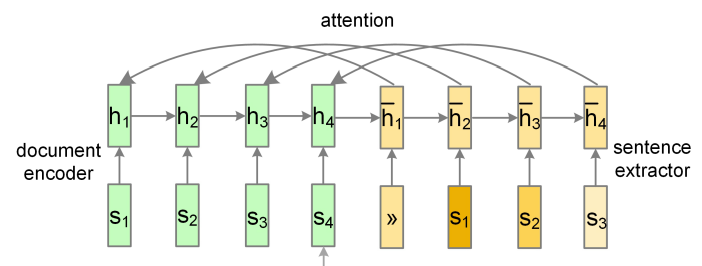
注意上面右边s和h_的位置差了一个
但是这种方法有点不好,
During training we know the true label pt−1 of the previous sentence, whereas at test time pt−1 is unknown and has to be predicted by the model.
所以我们必须把这个东西想一个办法搞定。
To mitigate this, we adopt a curriculum learning strategy,at the beginning of training when pt−1 cannot be predicted accurately, we set it to the true label of the previous sentence; as training goes on, we gradually shift its value to the pre- dicted label p(yL (t −1) = 1|d).
就是开始的时候用真正的label 后来用训练出来的label 这样我们的模型会从简单到难。
Word Extractor
这一部分和以前的东西很像,但是作者提出了一个 层次化的attention模型:
at time step t, the decoder softly attends each document sentence and subsequently attends each word in the document and computes the probabil- ity of the next word to be included in the summary
这个就是一个生成式的方法:
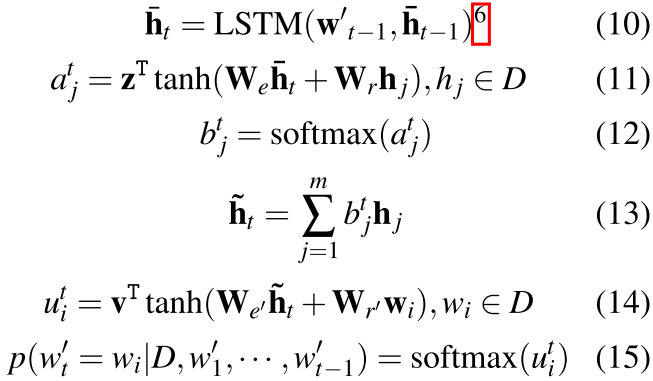
首先对于每一个输入的字,也就是我们预测的 记住这里的第一行的ht还是上面sentence extractor的ht
然后 我们开始得到第一个attention 也就是ajt 可以看到是以前所有的document sentence的,attention来源是当前的h_t
然后我们对于文章中的所有的句子的attention weight做softmax 然后以前文档的这个就表示出来了,呵呵就是表示了一下文档,然后用这个和每个文档中的词结合在一起然后生成了这个attention,最后输出就是文档中每个词的概率(当然还有停止符),
这个模型 呵呵呵呵
作者还在这个文章中用了一点encoder-decoder的方法预训练了一下CNN。
To improve the model, we propose to pre-train the convolutional sentence encoder to capture sentence semantics. Specifically, we use each sentence embedding derived from the CNN to predict every word in the sentence. 就是 autoencoder

但是这个工作作者没哟公布代码。以后我们要随时关注这个代码 并且看看他的数据集。
回复列表: