这个论文(我感觉)非常烂,竟然也投到了NPIS中去了~~~
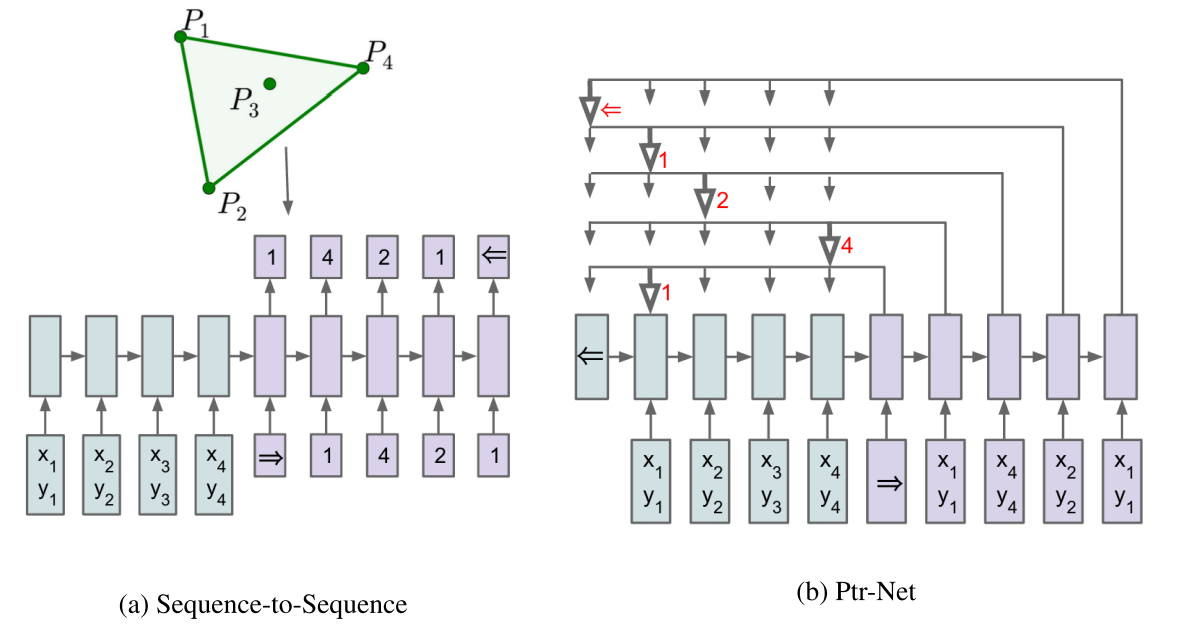
核心思想就是以前的s-to-s是在每次解码的时候输出字典中的一项,但是这个字典大小是固定的(比如在NMT里面就是目标语言此表的大小)
但是现在,我们每次解码器输出的softmax维度是变的了,怎么弄呢?首先还是编码一点没变,但是解码的时候,输出是针对于输入的了
公式如下:
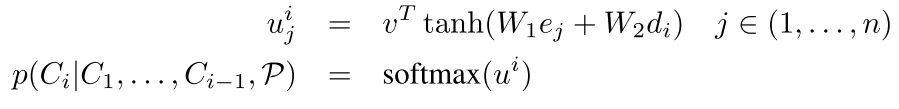
也就是在解码的时候还是会有一个di,然后它和编码器中的每个隐含层加权求和,然后输出一个值u 最后这个u再softmax一下就是输入中每个状态的概率,然后就可以输出了,呵呵呵
这个可以用在自动文摘上面(extractive类型的)
但是作者只是在一些算法上面进行了实验
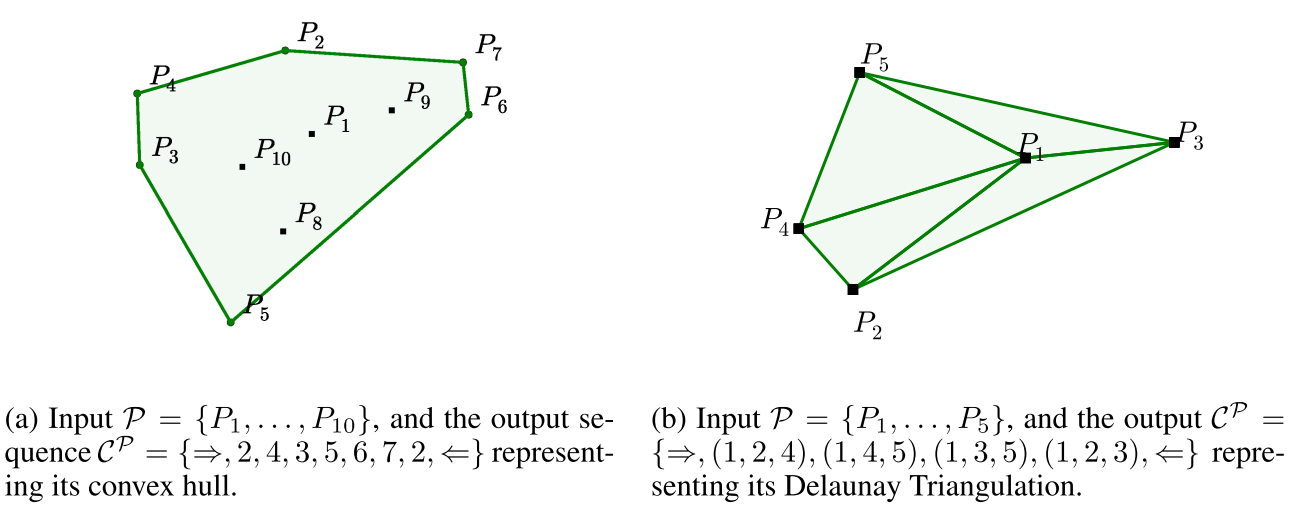
可以看出来效果应该也是有
但是有点太简单了 而且代码也是 hidden的 呵呵呵呵
回复列表: