句子对的相似度 不解释
============================
首先假设是这样


模型整体是这样
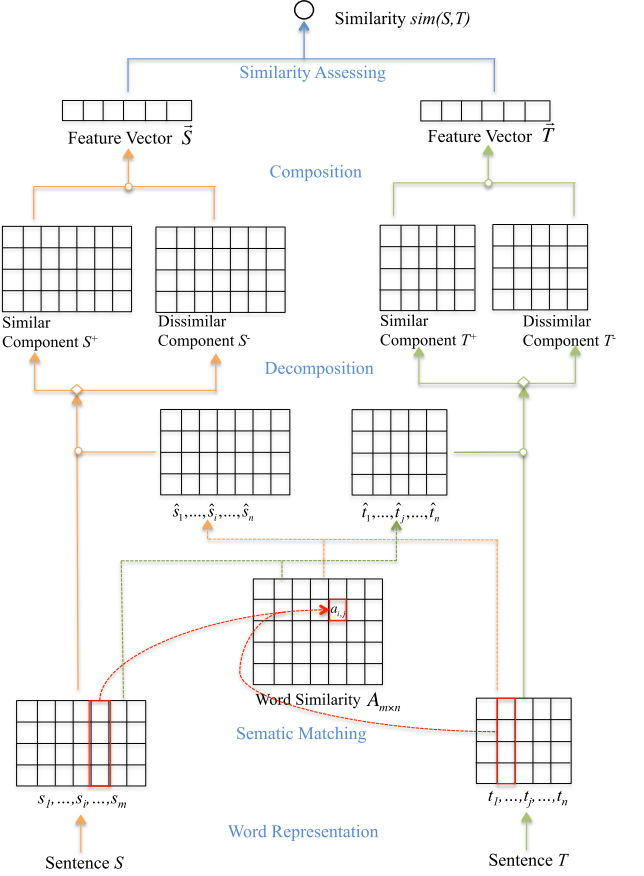
首先来了一个句子 首先肯定是词向量
然后两两计算相似度
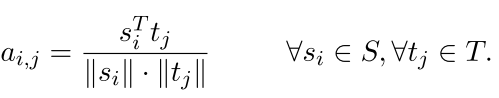
s是源语言 t是目标语言 就是两个句子对
为了找到源语言句子中的某个单词si的近似表达 我们可以这样
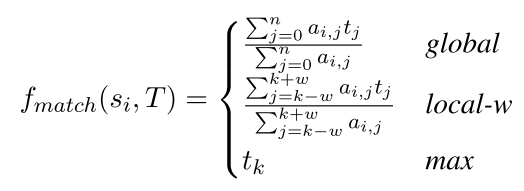
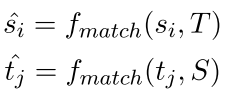
最后的sihat是上面三个的加权平均 注意这里的sihat表示的是在目标语言中的表示的组合 你看看上面那个t都是目标语言的
然后是解码 这一部分把刚才得到的sihat再次解码到相似的和不相似的部分 做法如下 他们设计了三个指标去区分相似的和不相似的
We implement three types of decomposition function: rigid, linear and orthogonal
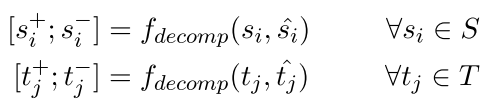
可以看到这个就是我们要解码的对象 就是找到相似的词语和不相似的词语
首先是rigid 也就是很严厉的
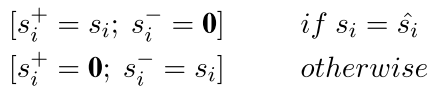
呵呵 两个向量在空间中怎么可能完全一致呢 这个sihat肯定是学出来的 不可能等于的 孩子
然后线性的就是
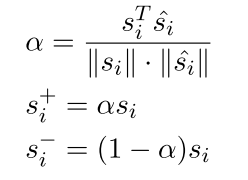
也就是相似的是自己 的一个加权(阿尔法)
然后我们再看看最后的那个正交的是什么样
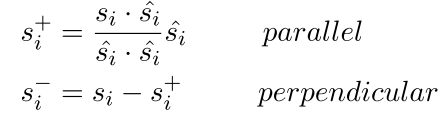
其实就是几何学上面的正交 这个很妙 然后把这三个再加权平均一下就得到了 这个解码的s+和s-
然后得到了 s+和s- t+ t-我们现在开始计算句子的表达
句子的表达其实就是刚才那个每个词的+- 最后还是cnn 但是现在cnn通道有两个 一个是model正的 一个是model负的
(作者原文的公式是这样的
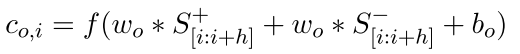
意思是+-都是用一个cnn filer 感觉不太好 因为你的参数都在这了 怕什么呢 最后一个max-pooling)
作者的实验比较奇怪
他是把S和T的cnn之后的表达拼到一起然后最后用一个线性模型映射到一个数上面 然后sigmoid强制转成0-1 呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵
最后用刚才那个sigmoid之后的数表示概率 极大似然 呵呵呵
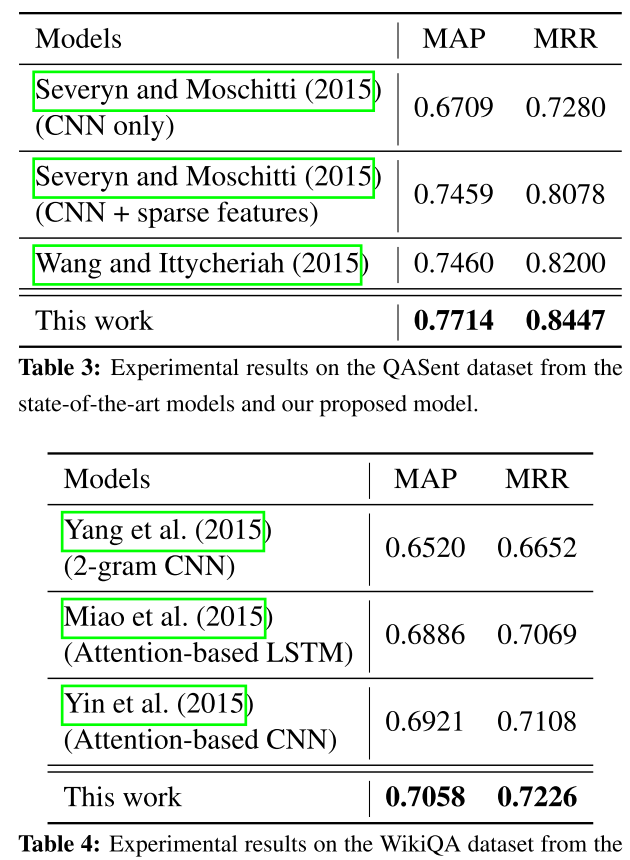
数据集有三个 AS:wikiqa qasent
PD: Microsoft Research Paraphrase corpus
回复列表: