这个还是压缩网络的方法,但是不是从重新搞模型的角度,而是从怎么存储,怎么优化的角度出发,像是研一学的信息检索的好多东西。
=====================
整体流程是这样的
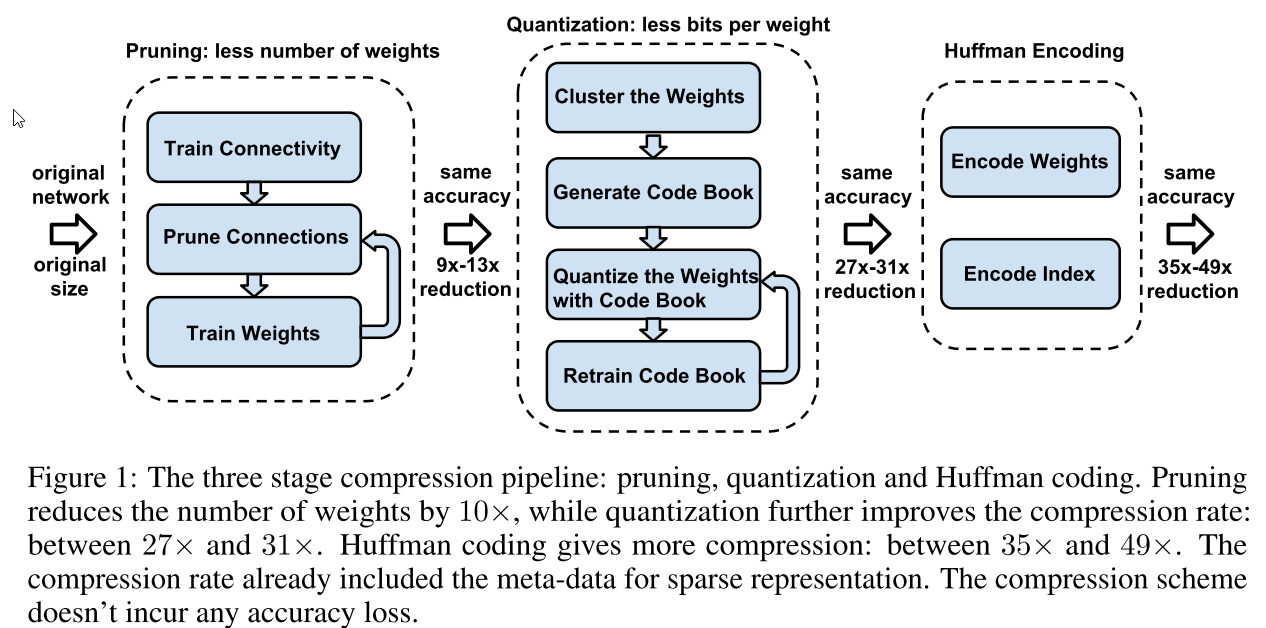
来来来 一步步的讲:
首先是 prouning:
we start by learning the connectivity via normal network training. Next, we prune the small-weight connections: all connections with weights below a threshold are removed from the network. Finally, we retrain the network to learn the final weights for the remaining sparse connections.
也就是先训练一个大模型,然后将(绝对)值小的weight给去掉,最后在剩下的这些还保留的weight上面继续训练
一般这一步可以将参数减小10倍左右
然后第二步是量子化
也就是把所有的weight分层,把各个层之间的weight统一表示 如下图:
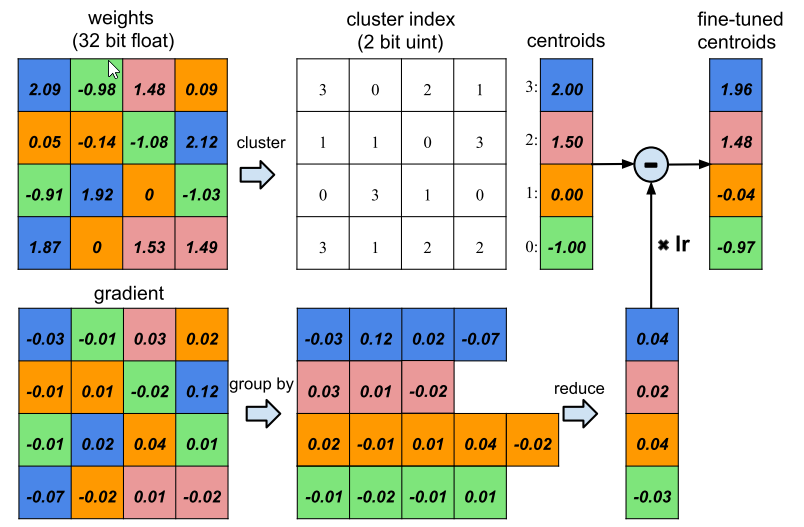
其中上面是表示的过程,然后下面是更新的过程,
注意 上面 我们把weight分成四类,然后每一类都有一个公共的值,然后再更新的时候,每一个类的更新值也是各自的更新值的求和。
for a network with n connections and each connection is represented with b bits, constraining the connections to have only k shared weights will result in a compression rate of:
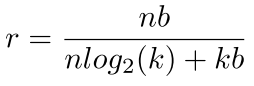
对于这种分层,他们使用的是weight shareing 也就是 k-means的聚类方法,最后有一个目标值就是:
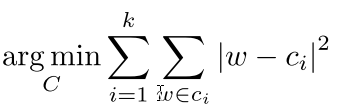
其中c是其中一类的参数,也就是上图中的蓝色或者红色橙色绿色中的一个
当然这些shared weight的初始值有很多种更新方法 有三个:
随机的: 随机选k个值从数据中然后就把这个定为初始值
根据概率密度: 是将cdf 中的等分线分成k个 然后看看这个k个的所对应的值
线性的:就是根据线性 从小到大平均分成k等分
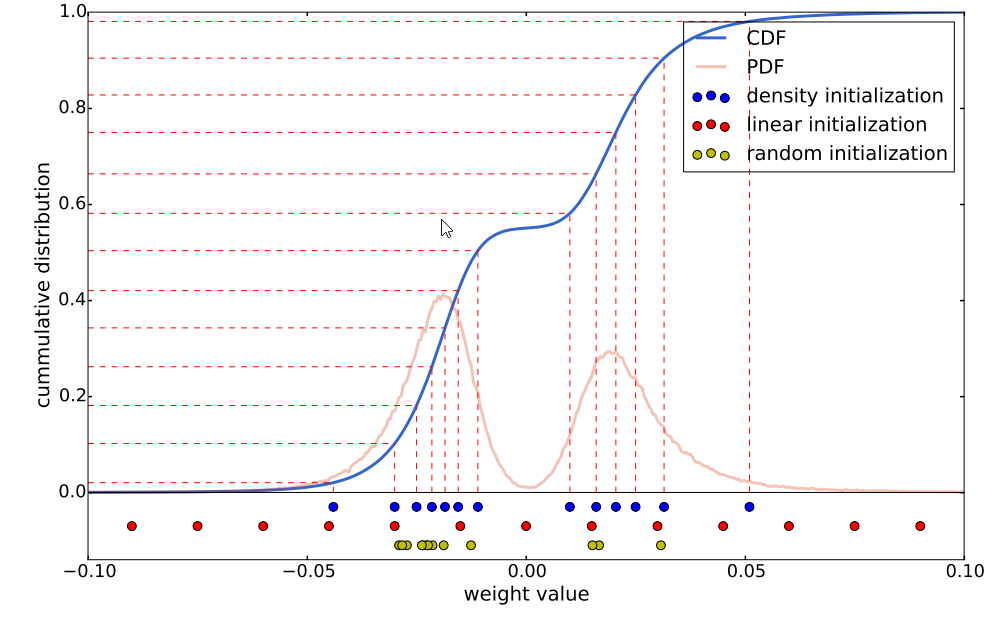
更新的时候就和上面的上面的那个图一样 就是所有的这个bin里面的权值共同更新
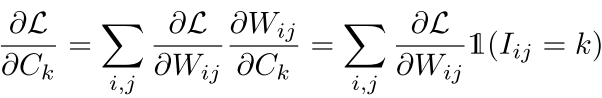
呵呵 都是一个工程的方法
回复列表: