这个文章应该是发表在IJCAI16上面的 做的是脑图像分析
为了解释LSTM内在的机制,作者做了如下的实验:
首先还是读课本,然后fMRI图像扫描课本,每四个词出一个人脑的图像(或者参数 叫做MEG)
然后再用LSTM刷一下这个课本或者这一段文章,然后看看刷完之后的LSTM内部的memory cell可不可以对应上 嘿嘿
这个文章不是让LSTM和fMRI的结果对应上 而是看看两者有没有联系,所以做的时候都是分别做的 两者没有任何的联系,只有在最后的时候才有一个映射矩阵将它们联系起来
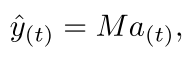
其中a是LSTM的y是fMRI的 这样只是优化这个M 其他的不优化
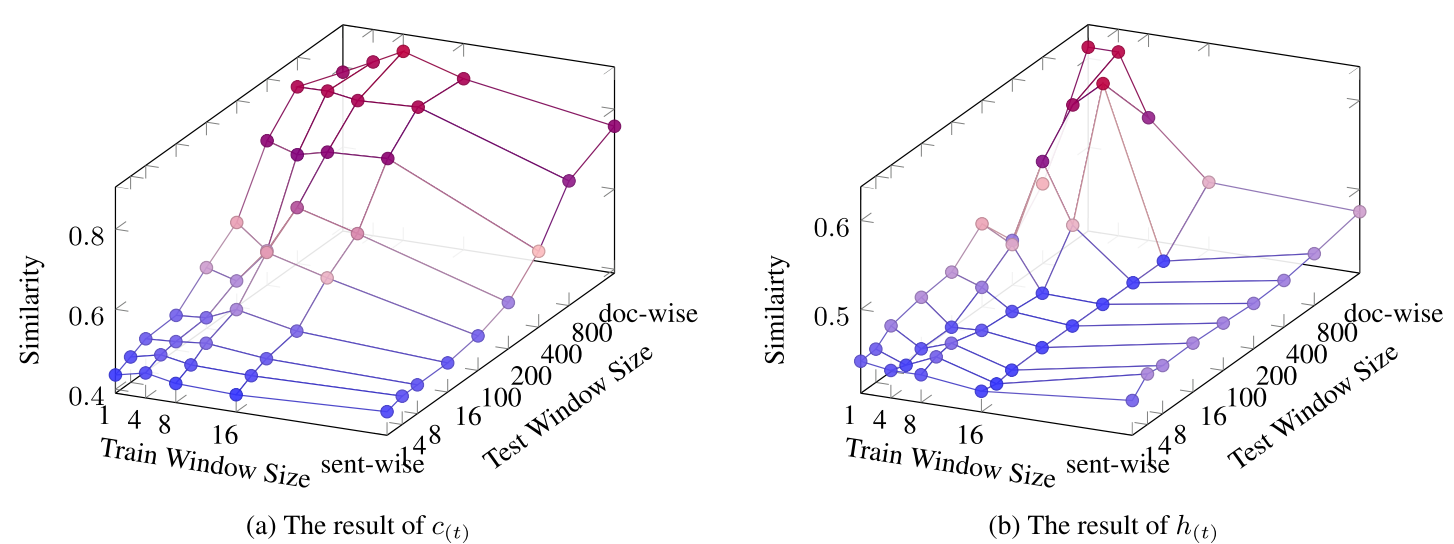
注意 因为作者这里用的LSTM开的窗口必须是4的整数倍 作者是每刷8个词生成一个LSTM的隐含层 然后和fRMRI的做对比,然后 因为人是一直在读的 所以我们LSTM窗口开的越长 应该越和fMRI拟合住
最后的效果是:
LSTM隐含层h没有memory 好
然后看看各个门的作用
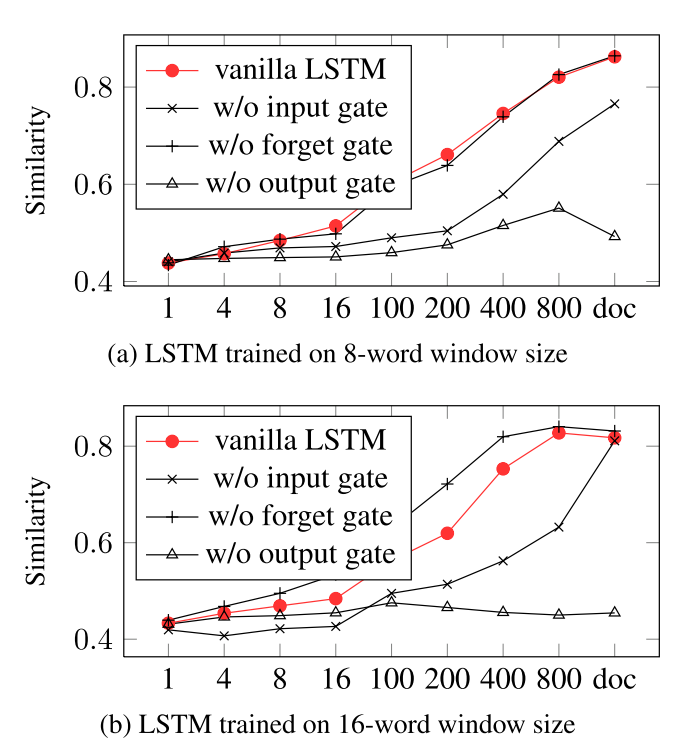
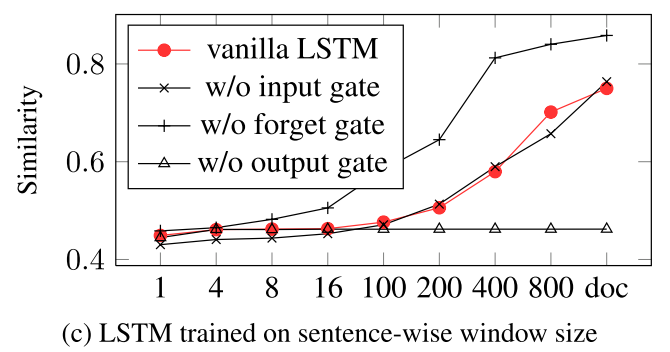
可以看出来还是去掉forget gate 没什么影响
It is obvious that dropping gates brings a fatal influence to the performance on the brain image prediction task. While it may have negative impact to drop input and output gates, the performances seem to been even improved when dropping the forget gates.
反正是一个很有意思的 工作 但是不知道最后的效果怎么样 因为没有代码 没有数据
回复列表: