这个是个好文章:
首先说一下什么是在深度增强学习里面的actor和critic
首先actor指的是由当前的状态执行一个动作 注意 输入是状态 输出是动作
critic是指的输入的是一个动作,输出的是一个得分,也就是对我们的当前的这个动作进行评价的指标
这个文章是用actor-critic来做序列预测 也就是我们常说的翻译模型
整个算法在下面这个里面

首先 我们要注意几个东西 就是以往的DQN里面 我们每次都是取一个reward最大的动作,然后根据这个值最大的动作来更新当前的参数
而且,传统的DQN里面,我们的输入是当前的状态,然后输出是6维的向量,表示六个动作,然后每一维有一个得分,所以这个DQN就是这样一个模式
但是在这这个里面 每次的对新的预测不是仅仅取最大(DQN)或者直接得到当前动作(SARSA),而是一个在所有的可能的动作上面的一个加权平均
就像上面的算法里面的5
首先说这个东西的预测是在整个序列输出完毕之后才弄 的 你可以看看这个里面是第4步是吧整体的序列都产生了
你看rt(y,Y)就是当前预测的词和正确的词的交叉熵或者一些评估指标 然后因为要对critic进行估计,不能仅仅有当前的这个reward,还要有
未来的reward,这个里面就是第5行的最后一个加权平均,其中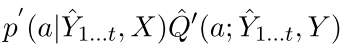 是由actor产生的
是由actor产生的
然后我们有了这个东西,先是要更新我们的critic,也就是第6行,但是注意,这里面没有直接更新Q,而是一个target critic Q',作者是这样解释的

也就是输入这样太动态了,所以我们需要对这个target qt也进行建模。
最后,就是更新actor,也就是生成词的那部分,注意这里我们使用的是一个目标是对所有可能的action做出惩罚,也就是到当前步的所有动作
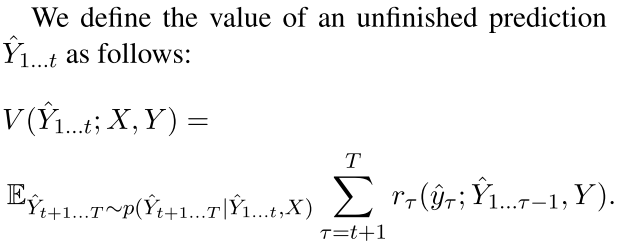
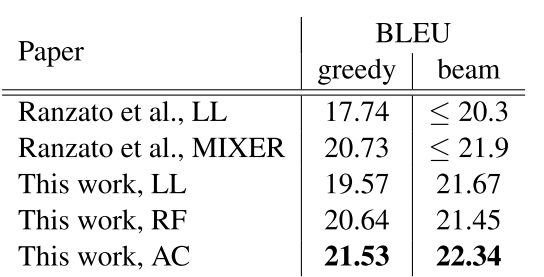
不错,最后在翻译上面做的
回复列表: