以前看过很多DRL的东西,最近有机会把他们都总结一遍。现在下面的是一个在推荐系统里面的用的DRL的东西。
作者阵容很豪华,又是Deepmind的东西
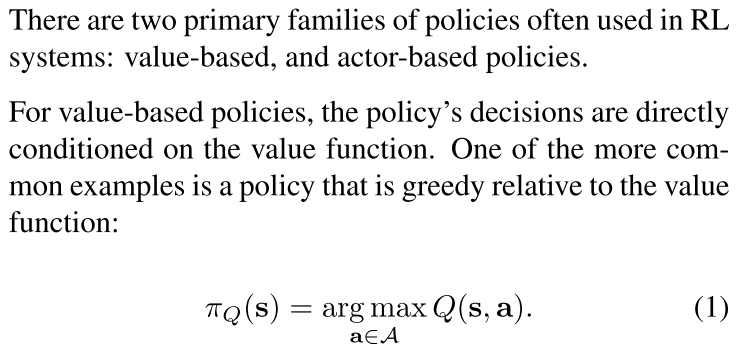
这个就是传统的DQN里面的东西,就是我们输出是有限维数的,然后动作还有reward就都有了。
但是我们最通用的一个步骤就是把action还有我们的状态同时输入到网络里面,然后把这个当成输入来评估reward,也就是我们通常所说的
actor-critic的方法。这个方法可以有效的利用我们其他的动作,就是这个动作可以影响其他的动作的值,因为这些动作都是embedding的。学习一个动作,可以
影响其他的动作。但是不幸的是 Unfortunately, execution complexity grows linearly with | A | which renders this approach intractable when the number of actions grows significantly.
但是actor-critic的方法也有一个问题就是不能通用化,因为在ac里面,那个actor的输出是一个softmax类似的东西,就是对每一个动作的一个打分,这样,还是
没有通用化
但是这个工作就是在这个上面进行了更改,也就是把action space泛化了
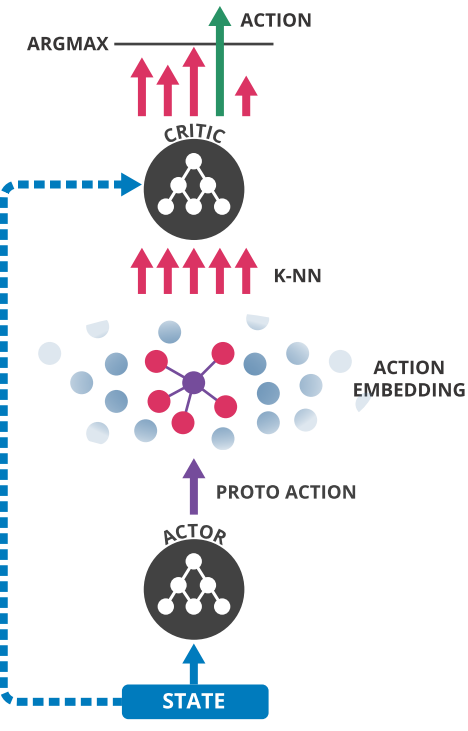
可以看到图中的东西,也就是每一个actor执行之后 是一个proto action 也就是action 原形,然后找KNN 来确定他的具体动作

但是我们第一步产生的那个a拔 怎么找真正的执行动作呢?
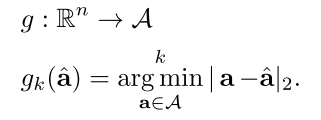
这个就是 我们有一个函数是将动作空间Rn映射到我们真正执行空间的,所以这里我们需要把这执行空间进行knn 就行了
但是有时候我们的一个动作的空间有可能处在一个周围都是非常高的Q值的空间,但是我们现在的这个动作却是非常低的Q值的,
In both of these cases, simply selecting the closest element to ˆa from the set of actions generated previously is not ideal.
作者在这里提出的一个东子就是
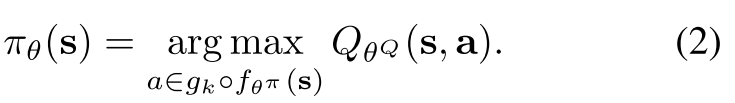
也就是不光光是选距离最近的,而是选择最后的Q值最大的,这个就是标准的DQN的输出层一样的形式么。实际上做的时候就是从a里面选择k个,然后比较
当前的critic参数情况下,这些动作的reward(当然最后还要更新这些critic)。
但是注意,这里的东西不是都可以反向求导的
---------------------
这个和我的对抗网络的时候很像,generator不能直接输出词向量
---------------------
所以在这个里面,他们不是这样找,而是最后的误差是这样找,但是训练的时候,也就是求梯度的时候,是求和的方式

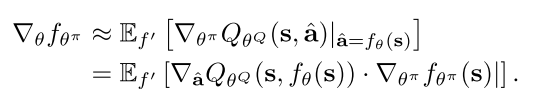
看到没有,就是所有的f'的输出求期望,而不是只选哪一个最大值输出的损失
我们可以看到另一个论文里面也有相似的介绍,也就是在连续的动作空间怎么执行我们的action 这个文章是去年的ICLR16的工作《CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING》
首先最开始的目标是这样的
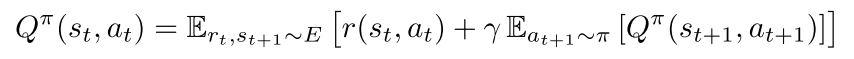
也就是标准的形式
如果我们的target policy也有的话 那么我们可以把上式那个期望给干掉
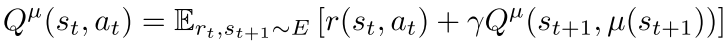
也就是有一个具体的评估损失的东西,这个
在以前已经介绍过

看看这个Q-Learning的定义,这个是我们以前曾经说过的 就是Q-learning最后只是选一个最大的u(s)来评估损失,也就是下一步的期望,然后乘以个折扣参数
这点说的很好
One challenge when using neural networks for reinforcement learning is that most optimization al- gorithms assume that the samples are independently and identically distributed. Obviously, when the samples are generated from exploring sequentially in an environment this assumption no longer holds. Additionally, to make efficient use of hardware optimizations, it is essential to learn in mini- batches, rather than online.
所以要用reply buffer 随机存储一些,然后更新的
最后这个算法就是:

看看和传统的DQN的区别

注意画框的部分。
最近还有几个DQN的工作,其中有一个是叫作《Dueling Network Architectures for Deep Reinforcement Learning》
也就是对抗的,但是我们知道这个里面每一个动作都是在当前的state的基础上面来进行的,所以可以看caption的那一本分,
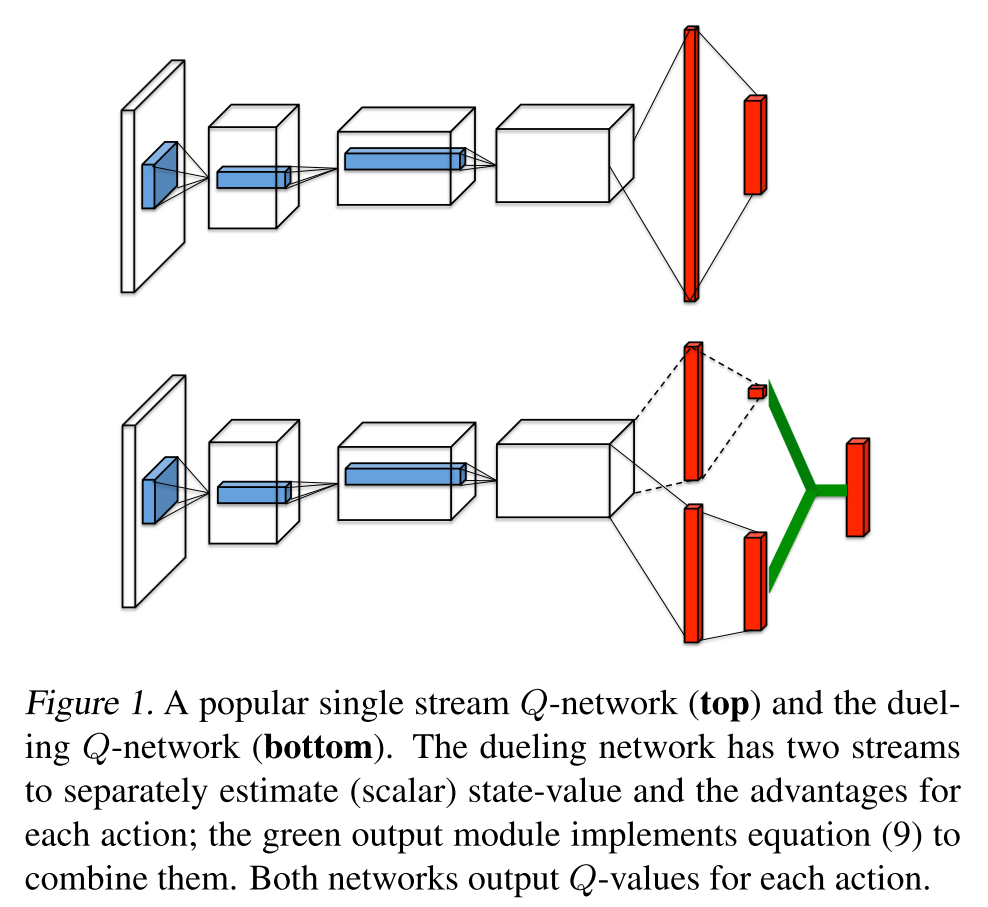
The dueling architecture consists of two streams that represent the value and advantage functions
This is particularly useful in states where its actions do not affect the environment in any relevant way.
--------------------------------
还有一个最近看到的一个名字叫作《LEARNING TO REINFORCEMENT LEARN》
核心是meta-learning在DRL上面的应用,我们先看看怎么定义这个meta-learning
At an architectural level, meta-learning has generally been conceptualized as involving two learning systems: one lower-level system that learns relatively quickly, and which is primarily responsible for adapting to each new task; and a slower higher-level system that works across tasks to tune and improve the lower-level system.
模型长的是这样的
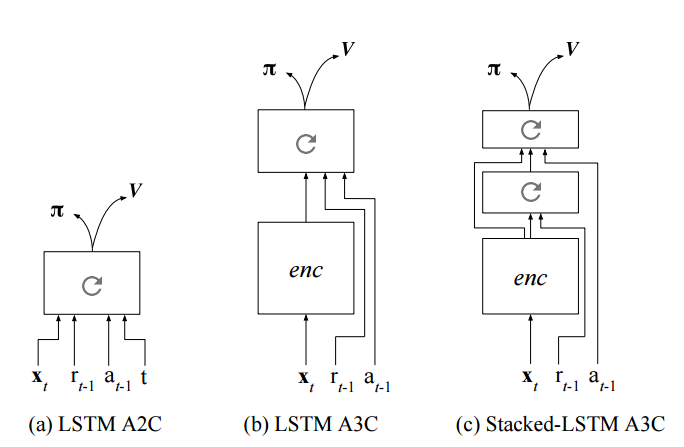
其实就是在里面变成了所有的历史 输出这个东西,不仅考虑当前的状态,还要考虑很久远的的历史,也就是所有的状态和输出。
回复列表: