今天第一次来写MC的文章,希望以后可以多中点。
--------------------------------------------------------------------------------
这个文章是微软研究院的人搞的,主要是一个根据用户的query来做数据集的方法。目标是1m,现在只有10w


这个文章发在NIPS2016 但是到现在数据都没放出,真是奇怪
但是预感新智元马上就要放出来了 哈哈哈
----------------------------------------------------------------------------------
首先是提出问题,现有的阅读理解的一些问题
1)One characteristic in most, if not all, of the existing databases for RC and QA research is that the distribution of questions asked in the databases are not from real users.
2)现有的数据都是来源于真正良好的数据源,但是实际的数据源可能非常有噪声,这使得像wikipedia这种就不好办了
3)就是现有的数据集的答案都是一个实体或者从文中的片段得到的,但是实际上我们需要好几句话才能回答一个问题,这个是我们的一个显著的针对阅读理解的
问题。
这个数据集里面的数据,可能是可以回答的,也可能是不可以回答的,也就是所有的问题
MS MARCO includes 100,000 questions, 1 million passages, and links to over 200,000 documents
Compared to previous publicly available datasets, this dataset is unique in the sense that (a) all questions are real user queries, (b) the context passages, which answers are derived from, are extracted from real web documents, (c) all the answers to the queries are human generated, (d) a subset of these queries has multiple answers, (e) all queries are tagged with segment information.
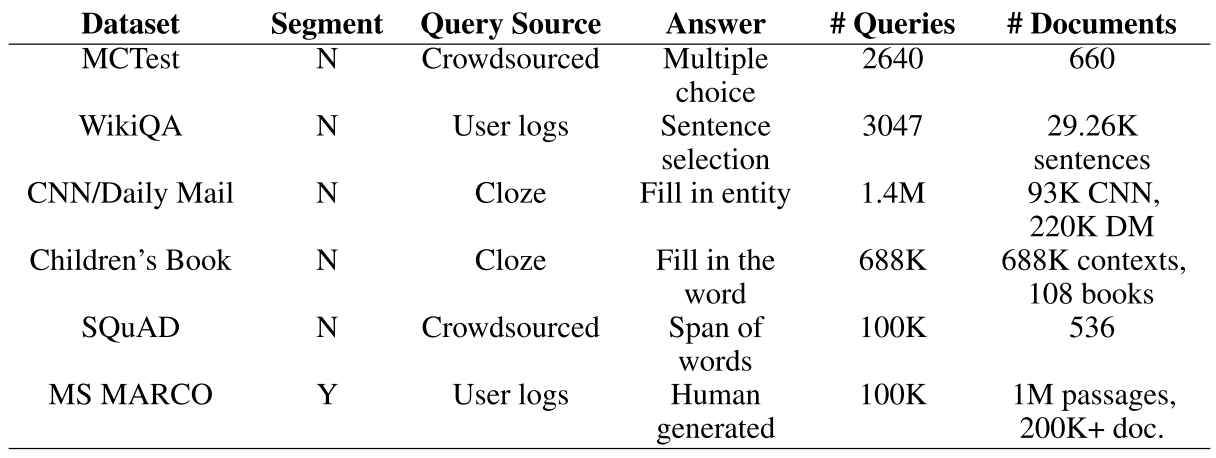
然后是下面对一些概念的定义

注意最后一个segment 他们把这个数据也自动的划分了种类,所以做的时候可以一类一类的做。分类包括这几类

最后的介绍

可以看到最后一个分类 他们用的是LDA加上SVM
但是 最后的问题类型,有点坑爹
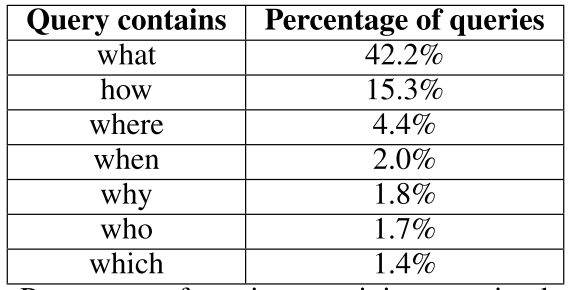
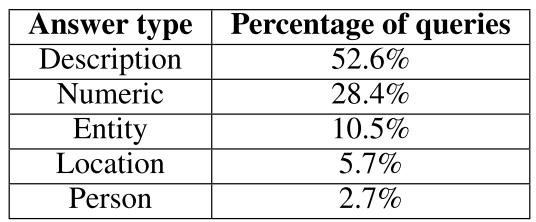
看到有这几种的只有60%左右,剩下都是没有问词的那种,但是how的很多,所以会很难
数据地址 http://www.msmarco.org/
回复列表: