以后再DRL的东西用在NLP的都放在这个下面吧
------------------------------------------------
Deep Reinforcement Learning for Multi-Domain Dialogue Systems
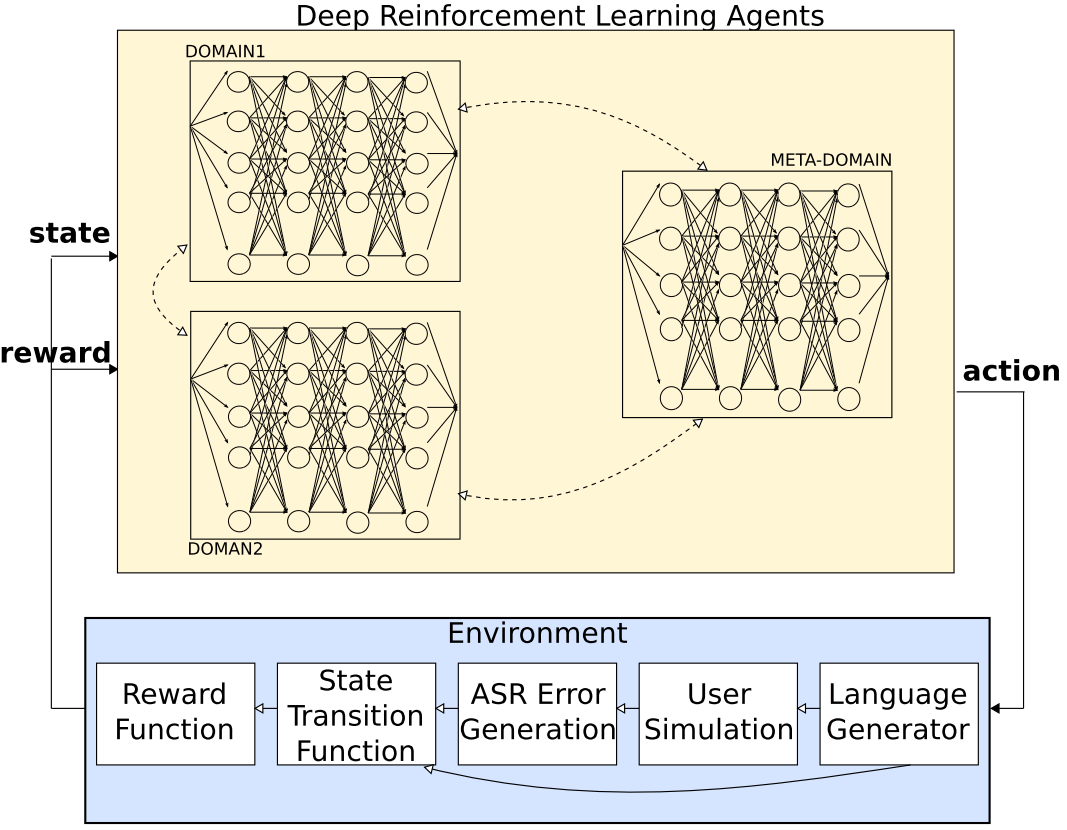
这个是主要有很多的domain,然后我们每一个domain都有自己独子的一个网络,但是有一个共同的meta-domain

用的还是DQN那一套,也就是取最大的期望回馈
-------------------------------
这个文章的一个主要的亮点在我看来是下面这几个东西
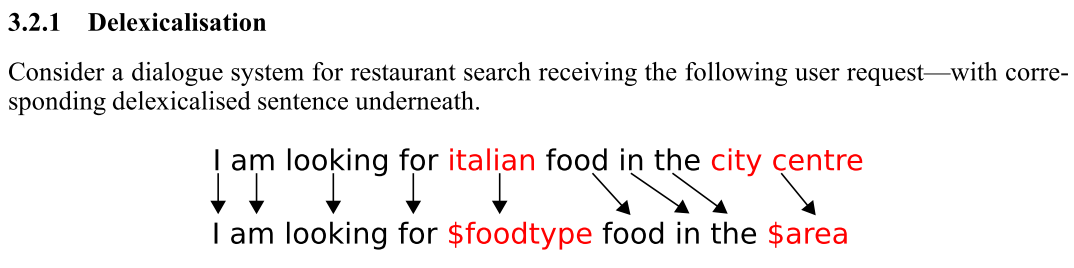
也就是让减少词语空间,做简化

也就是把不常用的词换成常用的词
回复列表: