这个主要是通过无监督从文本中提出一些concept的东西,我感觉很妙
------------------------------------------------------------
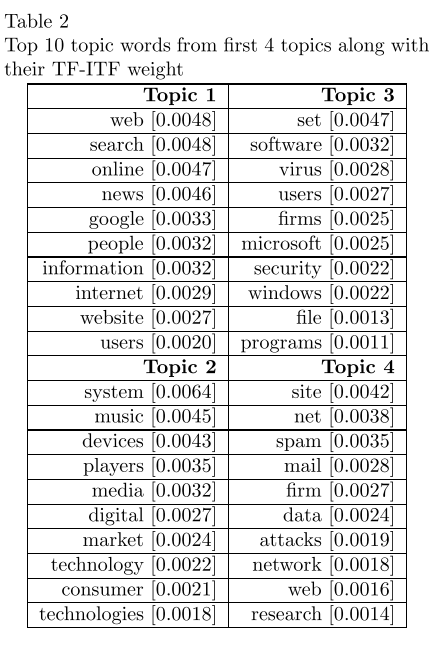
过程就不细说了,首先是通过LDA提取出一些主题,还有一些词在这个主题下的概率 就是传统LDA的那一套

然后我们可以对词语进行排序,当然是通过他们的TF-ITF,这个T是topic的意思,也就是把原来的document换成了topic,因为这里是为了要对topic进行建模。
然后有了这些指标 我们再进行下一步 就是提取一些关键的词
This step is followed by a sentence extraction pro- cess in which all the sentences which contain the topic words which have high tf-itf weight are extracted.
也就是找出那些含有这些高频tf-itf的词语
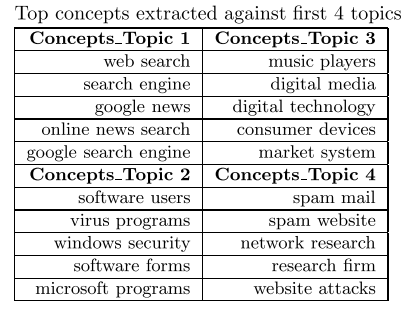
最后,通过一个pos工具 找出那些 Noun + Noun, Noun +Adjective and (Adjective / Noun) + Noun,也就是相连的词语,注意这些词语是从那些包含主题词的句子中抽的,不一定是主题词,只不过是有这种语法形式。

这样就完成了概念抽取的过程
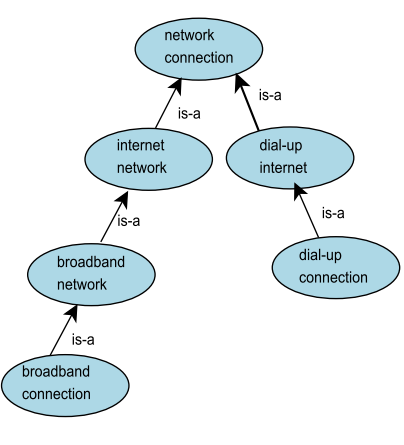
然后是概念分类,这里用了一个结构化的方法,就是看一个概念和另一个概念出现的频次的比例

回复列表: