这个文章我怎么感觉有点牵强附会呢……
又是deepmind的东西
ABSTRACT
We use reinforcement learning to learn tree-structured neural networks for com-
puting representations of natural language sentences. In contrast with prior work
on tree-structured models in which the trees are either provided as input or pre-
dicted using supervision from explicit treebank annotations, the tree structures
in this work are optimized to improve performance on a downstream task. Ex-
periments demonstrate the benefit of learning task-specific composition orders,
outperforming both sequential encoders and recursive encoders based on treebank
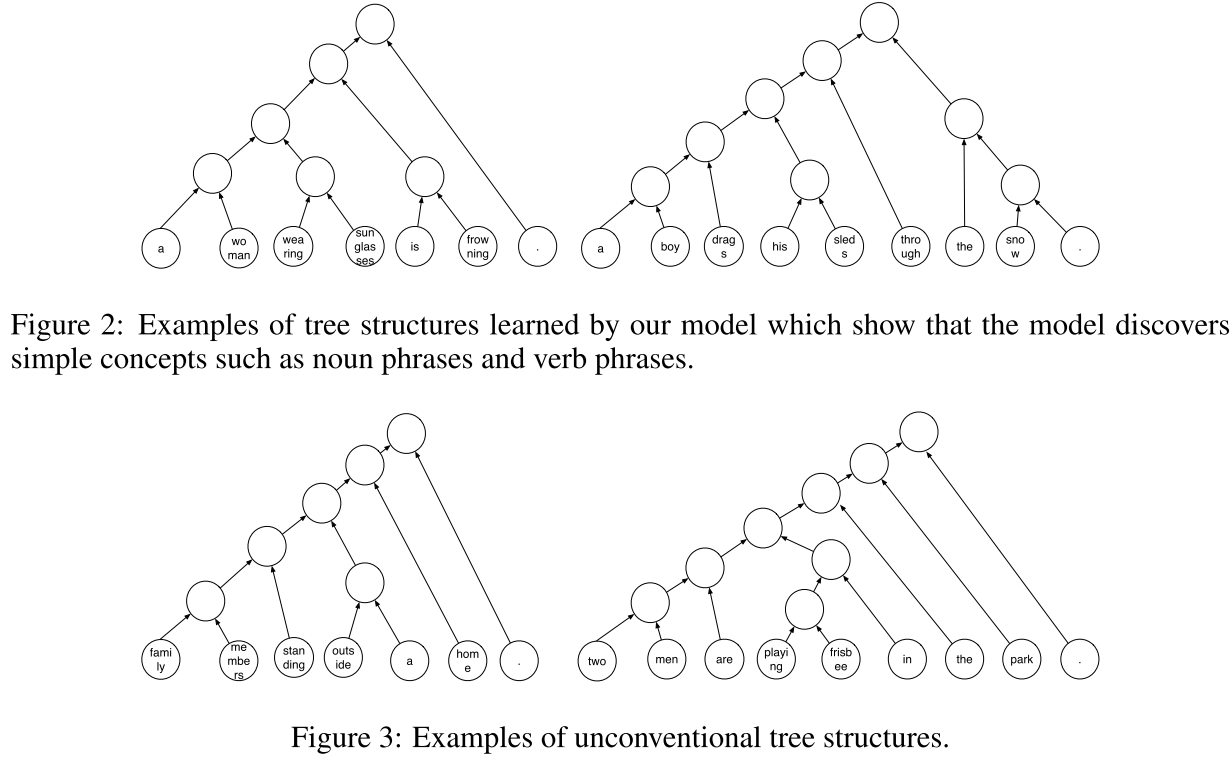
annotations. We analyze the induced trees and show that while they discover
some linguistically intuitive structures (e.g., noun phrases, simple verb phrases),
they are different than conventional English syntactic structures.
首先这个文章主要是为了用tree结构实现句子表达,并且最后在downstream的任务上能取得不错的成绩。
当然一般的tree都是事先给定的,这个任务里面作者用增强学习决定这个树的结构
model
Tree-LSTM 首先得有一个表示树的结构,就是我们如果已经有了一个结构了,就是一个树的结构,怎么表示其中节点的embedding
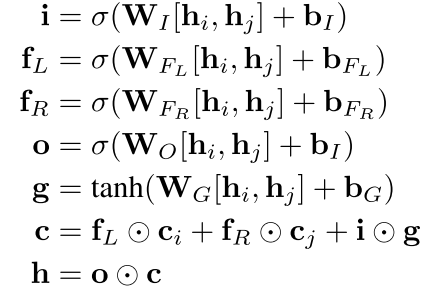
看到了就是在传统LSTM里面加入了左节点和右节点,很简单。注意这里没有什么输入,只有左节点右节点
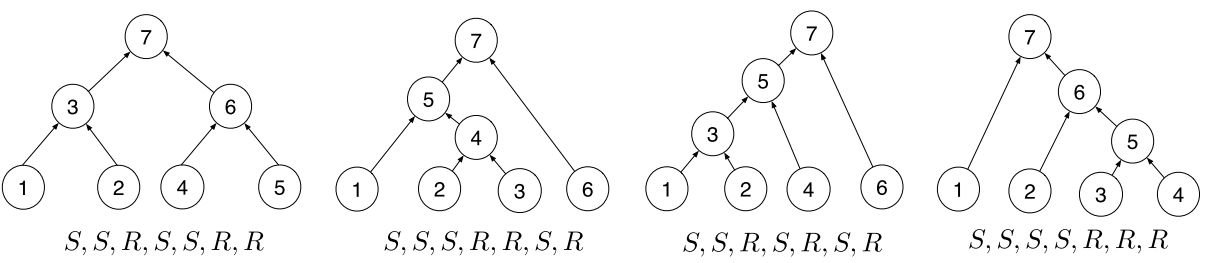
然后就是这个树的生成步骤了,作者用的是 [SHIFT,REDUCE]操作,SHIFT就是 把当前的词压入栈然后将指针指向下一个词。
而reduce就是把将栈里面的两个元素取出,浓缩成一个(用的是上面那个TREE-LSTM)然后再把这个元素压回去,但是指针不动
下图是一个例子
Tracking LSTM
如果只用刚才那个树——lstm的话,那么每次只有两个节点被model,所以作者在上面的那个LSTM里面加入了一个新的context-Information
也就是标准的LSTM,这个LSTM的输入是栈顶的两个元素以及当前指针pointer指向的词,然后这个东西在每次reduce的时候会将它的输出加入到tree-lstm里面
就不光是上面的那个hihj了,而是多了一个
----------------------------------
重点来了,就是增强学习
首先以前人家的任务里面这个tree的结构都是已知的,也就是我们的这个reduce还有shift动作都是可以直接学(训练集有测试集没有)或者用的(训练测试集都有树结构)
但是现在的任务里面很可能这个里面没有树结构,所以需要用增强学习的思想去学习这个动作
作者这样说:
We do not place any kind of restrictions when learning these structures other than that they have to be valid binary parse trees, so it may result in tree structures that match human linguistic intuition, heavily right or left branching, or other solutions if they improve performance on the downstream task.
We parameterize each action a ∈ {SHIFT , REDUCE} by a policy network π(a | s; W R ), where s is a representation of the current state and W R is the parameter of the network.
然后这个actor只是一个两层的MLP,输入是栈顶的两个元素以及当前指针的输入。
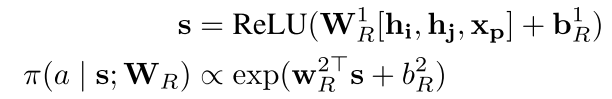
由于只有两个动作,所以比较好确定
现在重点来了!!
If a is given as part of the training data, the policy network can be trained—in a supervised training regime—to predict actions that result in trees that match human intuitions. Our training data, on the other hand, is a tuple {x, y}. We use REINFORCE (Williams, 1992), which is an instance of a broader class of algorithms called policy gradient methods, to learn W R such that the sequence of actions a = {a 1 , . . . , a T } maximizes
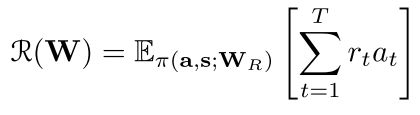
rt是每一步的reward,这个有意思哈。就是如果是有监督的,也就是动作给了,那么这个policy可以直接用有监督的学,那这还是增强学习么?
如果是无监督的,那么用了一个 REINFORCE 算法。
现在就是我的问题的时间:
增强学习往往是步数不确定,所以要跑好几轮然后最后有有一个reward,或者一直有输出最后有一个reward。但是总是步数不确定
但是这个里面只是用了一个期望,假设我们的任务是情感分类,那么最后的reward就是
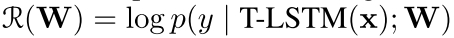
where we use W to denote all model parameters (Tree LSTM,policy network, and classifier parameters
实验不说了,反正没有特别好
几个学出来的树结构
回复列表: