HYPERNETWORKS
这是一篇介绍神经网络里面权值的东西
以前我们的神经网络里面 权值都是随即初始化的,然后再不断的学习。 现在这个里面,权值是用另一个网络产生的,然后
产生一个大的权值矩阵,这个产生权值的矩阵叫作超网络,也就是hyperNetwork
通常比较大的权值矩阵都比较大,所以很难存储或者初始化,训练肯定就更难了。
在这个文章里面,作者是针对这样一个问题进行求解。
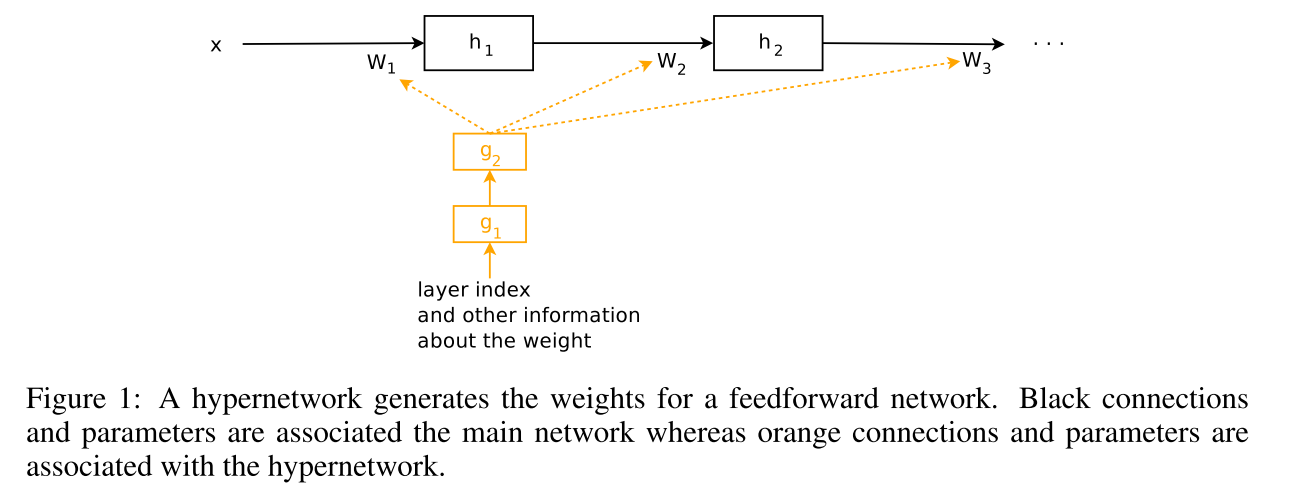
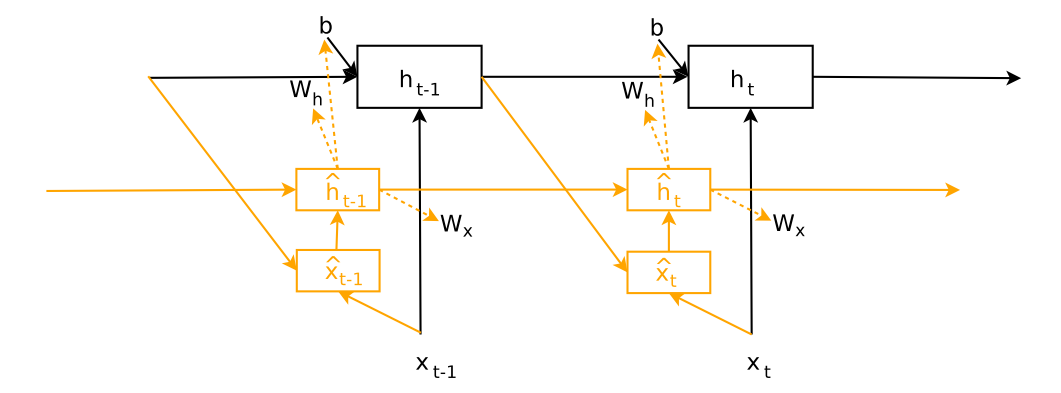
这个是最简单的超网络示意图,也就是黄色的就是我们的超网络,也是要学习的部分,而它产生的这个权值矩阵w1,w2则不用学。
这篇文章作者用了两个具体的网络的例子,一个是cnn还有一个是lstm
In this paper, we view convolutional networks and recurrent networks as two ends of a spectrum.
具体的
对于cnn 假设这个网络有D层,然后每一层有Nin*Nout个核,每个核实f_size*f_size的大小
那么这一层总体的参数就是
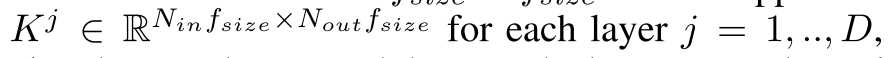
那么怎么产生这么一个参数呢?
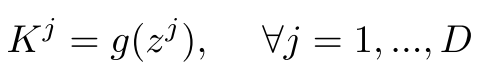
其中这个g就是我们的超网络,z代表的是layer embedding,也就是0-D映射到一个连续空间。
然后,在这个里面作者将这个超网络分成两层,也就是两层的MLP,其中第一层是输入是z(Nz维)然后它产生Nin个d维度的向量,
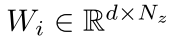
这就是每一个的参数,其中d是这个超网络中间层的个数。然后最后一层也就是输出输出就是一个f*f*Nout的一个东西,那么现在
总体的公式就是
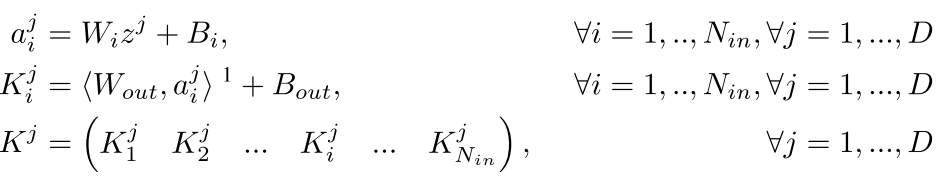
其中W_out是
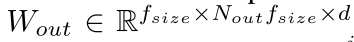
所以我们可以看到,因为使用了中间隐含层d 所以总体参数会小很多
-------------------
LSTM里面
也就是每一步的权值其实是变化的,有意思吧,不是永远保持恒定的了,而是根据超网络进行改变。

可以看到参数是由一个网络生成的,这个z就是我们要出去的东西,你可以看到这个z不是像cnn里面那样是直接有一个层数的embedding,而是根据输入来的
但是这样呢 我们可以看到Whz很大,在实际中很难得到应用
所以我们就把这样的一个网络急需缩小
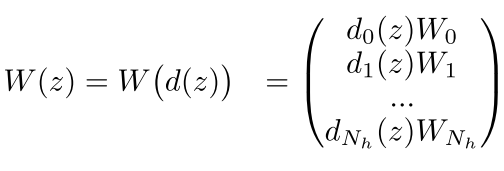
可以看到这里的W(z)就是上面公式(5)的那个左边的东西,我们可以看到在这个里面,我们还是有Nh个矩阵,每个矩阵可就是Nh*Nz
大小的,但是我们用这个d(z)来对这个矩阵进行扩张或者缩小,这个d(z)是一个向量,只是为了对矩阵的每一列进行缩放
现在,可以将上式写成
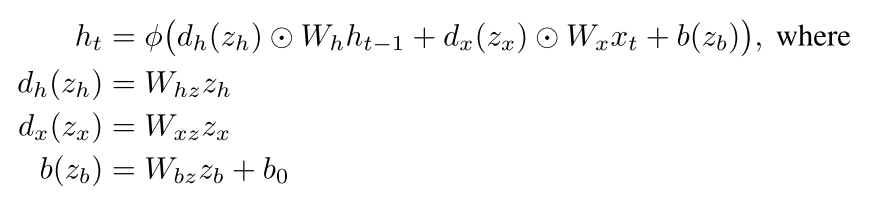
LSTM里面
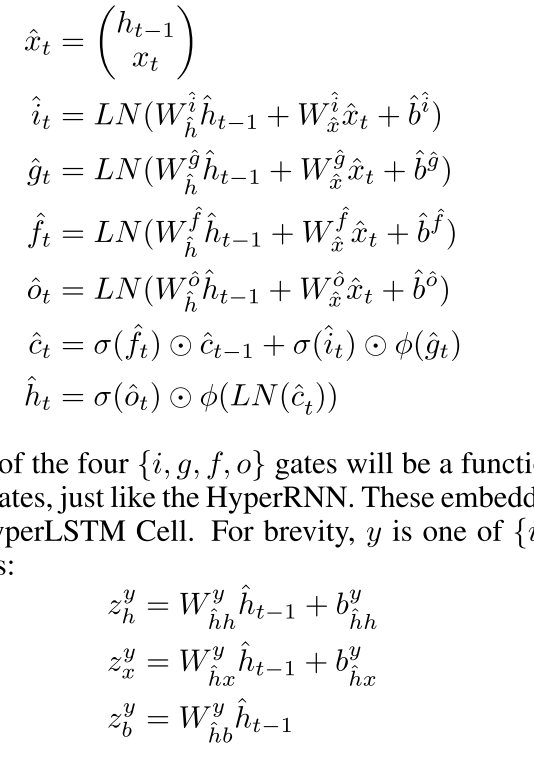
其中LN表示Layer Normalization
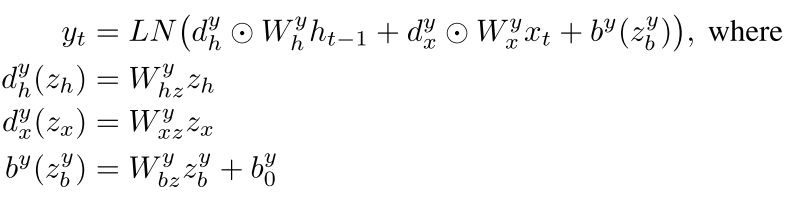
但是这样做参数空间会大很多,我们也要随时根据这个来进行处理。
在实验里面,作者有一个东西很有意思,也就是对这个LSTM参数的值进行打印

可以看到确实随着这个读入的改变,参数也是在变的。
回复列表:
匿名发表于 April 24, 2019, 5:27 p.m.
非常棒的blog!!