Contextual RNN-GANs for Abstract Reasoning Diagram Generation
这个其实是在动态视频上面做的
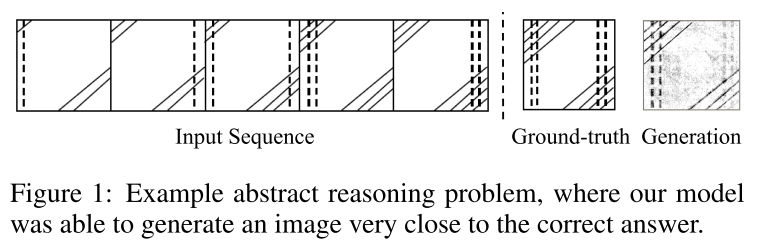
任务就是这个
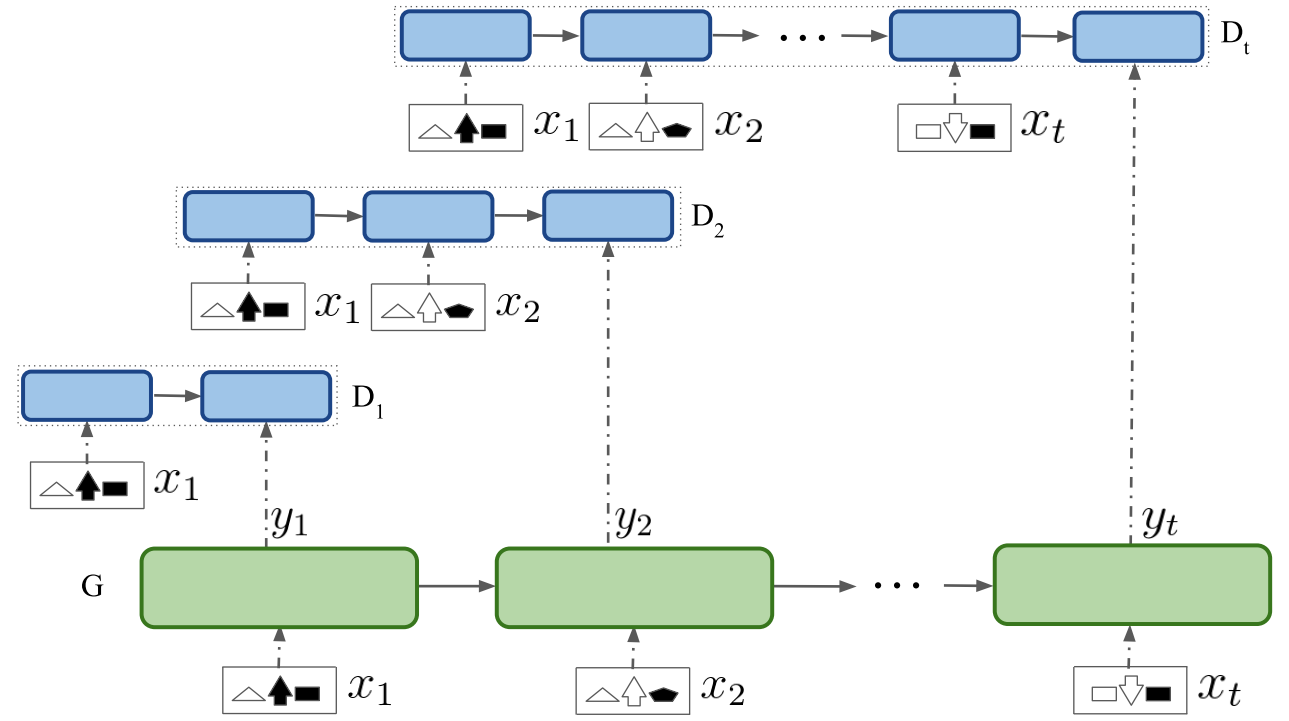
上面就是这个整体的模型,可以看到他的那个G也是根据上下文来生成的
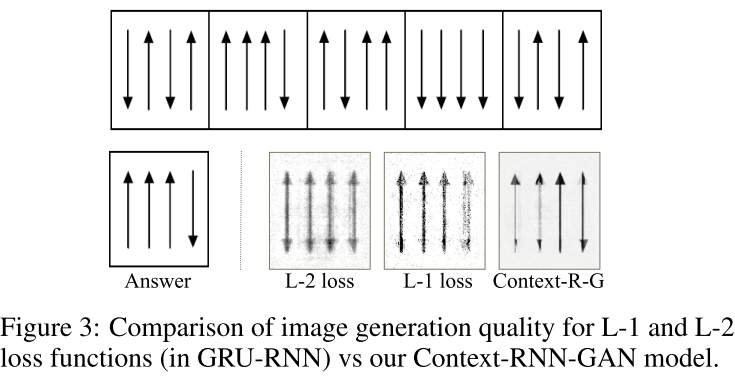
这几个baseline|model 可以看到以前的 那种,就是类似语言模型的那种,以L2或者L1为目标函数的预测,很模糊,这个和我们的VAE很像,也是
很模糊,因为最后的目标值是我们真正的目标。
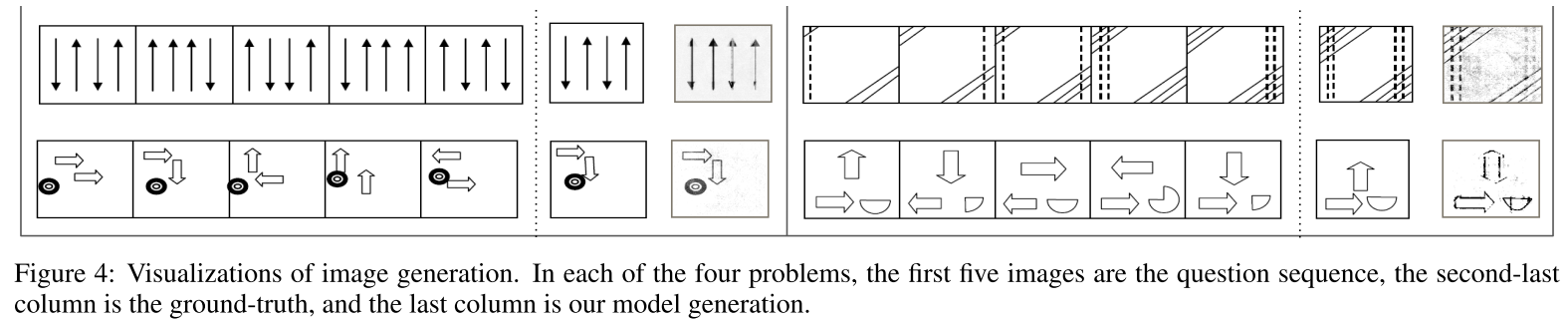
Contextual RNN-GANs for Abstract Reasoning Diagram Generation
这个其实是在动态视频上面做的
任务就是这个
上面就是这个整体的模型,可以看到他的那个G也是根据上下文来生成的
这几个baseline|model 可以看到以前的 那种,就是类似语言模型的那种,以L2或者L1为目标函数的预测,很模糊,这个和我们的VAE很像,也是
很模糊,因为最后的目标值是我们真正的目标。
回复列表: